
Werbung
Heute ist es soweit: NVIDIA läutet mit der GeForce GTX 1080 und GTX 1070 auf Basis der Pascal-Architektur den diesjährigen Neustart bei den Grafikkarten ein. In Kürze wird wohl auch AMD seinen Beitrag zu diesem Thema leisten. Vor zehn Tagen lud NVIDIA die gesammelte Fachpresse nach Austin ein und präsentierte dort die Neuigkeiten rund um die neuen Karten. Heute nun können wir weitere Informationen von diesem Event präsentieren und liefern auch die dazu passenden Benchmarks. Neben der Vorstellung der Architektur, dem Referenzdesign als Founders Edition sowie den bereits angesprochenen Benchmarks werden aber auch die neuen Technologien eine wichtige Rolle spielen.
Nach langer Zeit nutzte NVIDIA in diesem Jahr wieder einmal die GPU Technology Conference, um eine neue GPU-Architektur anzukündigen. Etwas überraschend wurde Mitte März die Pascal-Architektur vorgestellt, der auch gleich die Ankündigung zur Tesla P100 folgte, dem ersten GPU-Beschleuniger, der die neue Architektur verwendet. Überrascht wurde die versammelte Fachpresse daher, da NVIDIA auch unter Ausschluss der Öffentlichkeit vorher nichts zu diesem Thema durchblicken ließ. Natürlich bezog sich die Vorstellung der Pascal-Architektur ausschließlich auf den Compute-Bereich, doch die potenzielle Rechenleistung ließ sich bereits ablesen. In einer ersten Analyse der Pascal-Architektur wurde schnell klar, was diese zu leisten im Stande ist.
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
NVIDIA geht mit der GP100-GPU in die Vollen – "All in" wie es der CEO Jen-Hsun Huang auf der Keynote zu sagen pflegte. 15,3 Milliarden Transistoren, 16 GB HBM2, eine Chipfläche von 610 mm² und ein ebenso komplexes Design für den Interposer sind die technischen Herausforderungen, denen sich NVIDIA angenommen hat. Mehrere Jahre sollen tausende Ingenieure an der Entwicklung gearbeitet haben. Schlussendlich soll das R&D-Budget für die Pascal-Architektur zwischen 2-3 Milliarden US-Dollar betragen haben. Das NVIDIA eine solche Hardware überhaupt zum aktuellen Zeitpunkt anbieten kann, hatten viele sicherlich nicht erwartet. Auf der anderen Seite aber macht die Ausrichtung der GP100-GPU klar, welche Ziele NVIDIA damit verfolgt. Der Stückpreis für eine Tesla P100 dürfte irgendwo zwischen 12.000 und 15.000 US-Dollar liegen – Preise dazu hat NVIDIA allerdings noch nicht veröffentlicht.

Für die GeForce GTX 1080 und GTX 1070 müssen wir zunächst einmal einen Schritt zurück machen. NVIDIA verwendet hier ein angepasstes Design, welches sich in vielen Bereichen deutlich von der GP100-GPU für die Tesla P100 Beschleunigerkarte unterscheidet. Auf eben diese Details gehen wir auf den folgenden Seiten ein. Hinzu kommen neue Technologien, die ebenfalls in Zukunft eine wichtige Rolle spielen sollen.
| Die technischen Daten der GeForce GTX 1080 im Überblick | |||
|---|---|---|---|
| Modell | NVIDIA GeForce GTX 1080 | AMD Radeon R9 Fury X | NVIDIA GeForce GTX 980 Ti |
| Straßenpreis | 789 Euro | ab 615 Euro | ab 620 Euro |
| Homepage | www.nvidia.de | www.amd.de | www.nvidia.de |
| Technische Daten | |||
| GPU | GP104 | Fiji XT | GM200 |
| Fertigung | 16 nm | 28 nm | 28 nm |
| Transistoren | 7,2 Milliarden | 8,9 Milliarden | 8 Milliarden |
| GPU-Takt (Base Clock) | 1.607 MHz | - | 1.000 MHz |
| GPU-Takt (Boost Clock) | 1.733 MHz | 1.050 MHz | 1.075 MHz |
| Speichertakt | 2.500 MHz | 500 MHz | 1.750 MHz |
| Speichertyp | GDDR5X | HBM | GDDR5 |
| Speichergröße | 8 GB | 4 GB | 6 GB |
| Speicherinterface | 256 Bit | 4.096 Bit | 384 Bit |
| Speicherbandbreite | 320 GB/s | 512,0 GB/Sek. | 336,6 GB/s |
| DirectX-Version | 12 | 12 | 12 |
| Shadereinheiten | 2.560 | 4.096 | 2.816 |
| Textureinheiten | 160 | 256 | 176 |
| ROPs | 64 | 64 | 96 |
| Typische Boardpower | 180 W | 275 W | 250 W |
| SLI/CrossFire | SLI | CrossFire | SLI |
Im Verlaufe dieses Artikels verwenden wir für die GPU auf der GeForce GTX 1080 den Modellnamen GP104. Gleiches gilt bislang auch für die GeForce GTX 1070, auch wenn wir hier eine Beschneidung hinsichtlich der Architektur sehen. NVIDIA hat noch keine technische Bezeichnung für die Chips benannt. Damit ein Vergleich zur GP100 der Tesla P100 möglich ist, nutzen wir zunächst den Namen GP104 für GeForce GTX 1080 und GTX 1070. Die Fertigung der GPU erfolgt in 16 nm FinFET bei TSMC. Die Anzahl der Transistoren gibt NVIDIA mit 7,2 Milliarden an. Die Größe der GPU liegt bei 314 mm².
[h3]Pascal-Architektur[/h3]
Weiterhin ein zentraler Bestandteil der Architektur sind die Streaming Multiprocessors (SM). Der Aufbau sieht Graphics Processing Clusters (GPCs), Streaming Multiprocessors (SMs) und Speichercontroller vor, die in einem bestimmten System organisiert sind. GP104 auf der GeForce GTX 1080 besteht aus vier GPCs, 20 SMs und diese wiederum besitzen jeweils zwei SM-Blöcke mit jeweils 64 Shadereinheiten. Damit kommt man auf insgesamt 2.560 Shadereinheiten (10x128). Neben den 128 Shadereinheiten befinden sich in jedem SM auch noch acht Textureinheiten, sodass wir hier insgesamt auf 160 Textureinheiten kommen. Das Speicherinterface ist 256 Bit breit. NVIDIA setzt den Speichercontroller aus Blöcken zu jeweils 32 Bit zusammen. Acht Render-Backends oder ROPs sind jeweils an einen Speichercontroller angebunden. Bei 8x 32 Bit (256 Bit insgesamt) sehen wir hier also 64 ROPs für die GeForce GTX 1080.

Die PolyMorph Engine beinhaltet auch eine spezielle Hardwareeinheit für eine Funktion namens Simultaneous Multi Projection. Die Kombination aus einem SM plus der PolyMorph Engine wird als Thread Processing Cluster (TPC) bezeichnet. Jeder Streaming Multiprocessor verfügt außerdem über 256 kB File Register, 96 kB Shared Register und 48 kB L1-Cache. Hinzu kommen auch noch 2.048 kB an L2-Cache.
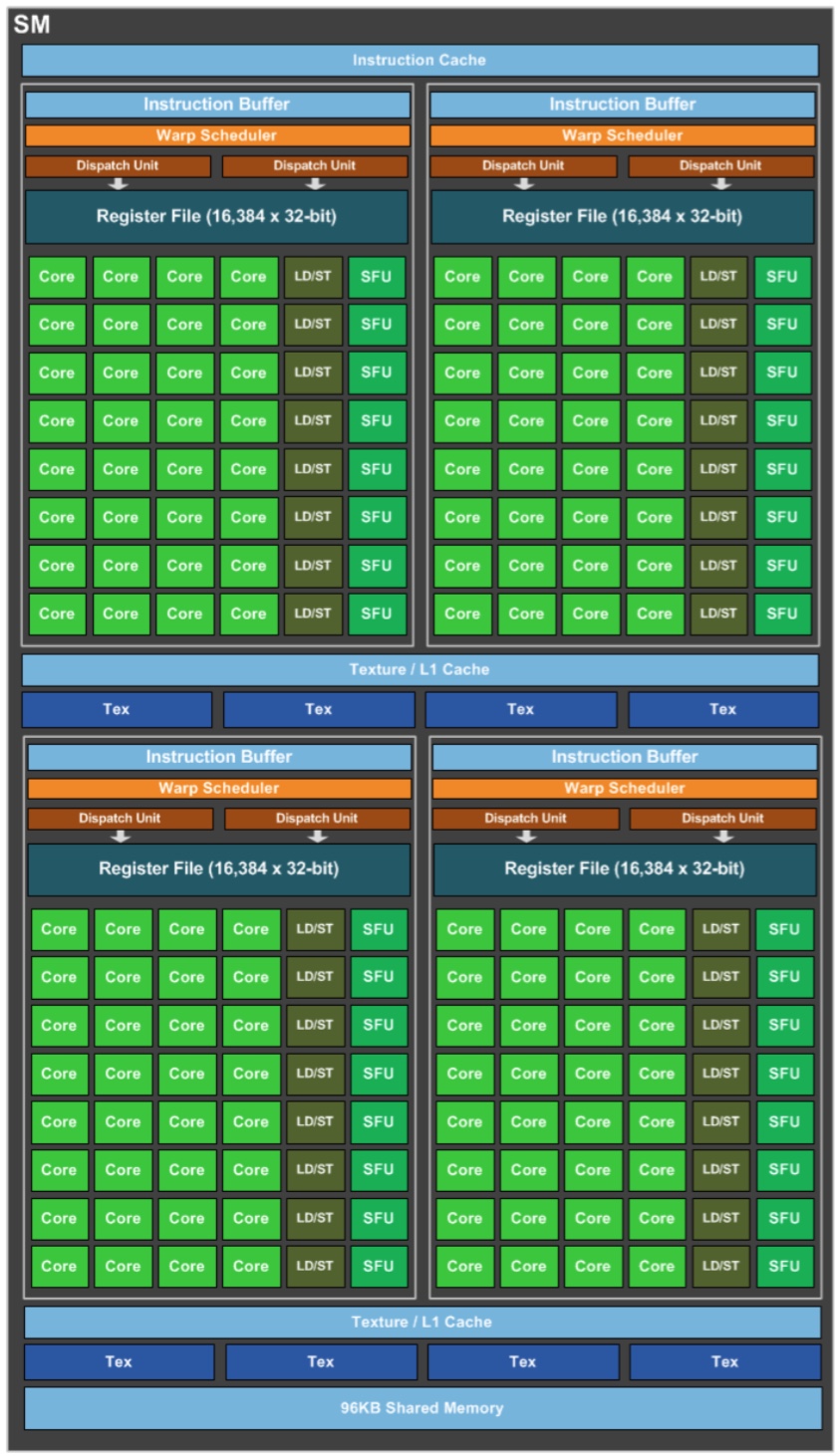
Vergleicht man die GP104-GPU der GeForce GTX 1080 mit der GP100-GPU der Tesla P100 fallen hier einige Änderungen auf. So verfügt die GP100-GPU über 64 Shadereinheiten pro SM und bei der GP104-GPU sind es 128. Außerdem haben sich die Register- und Cache-Größen leicht verändert. Damit hat NVIDIA erstmals innerhalb einer Architektur nicht nur das Grundgerüst entsprechend angepasst (FP64-Einheiten hinzugefügt und die grundsätzliche Anzahl an Shadereinheiten variiert), sondern teilweise eine Restrukturierung der Architektur vorgenommen, um diese den Bedürfnissen einer Tesla- oder GeForce-Karte anzupassen.
[h3]Strom- und Spannungsversorgung[/h3]
Bei einer Fertigung in 16 nm bei mehreren Milliarden Transistoren rückt die Strom- und Spannungsversorgung mehr und mehr in den Fokus. Jeder einzelne Bereich der GPU muss mit einer möglichst stabilen Spannung versorgt werden, weshalb dedizierte Schaltkreise vorhanden sind. Je umfangreicher diese Versorgungs-Infrastruktur in der GPU ausgebaut wird, desto stabiler sind die Spannungen. NVIDIA hat bei der Entwicklung der Pascal-Architektur bzw. der GP104-GPU tausende von Simulationen durchgeführt, um das letztendlich effizienteste Verhältnis zwischen der Spannungsversorgung und dem Takt der GPU zu finden – dies gilt sicherlich auf für die GP100-GPU der Tesla P100.

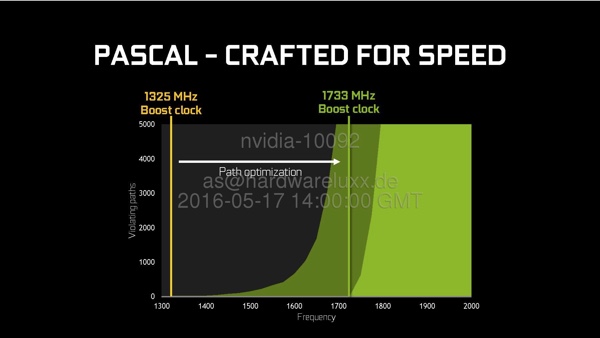
Begonnen hat die Entwicklung mit einem Verhältnis von etwa 1.300 Voltage Paths, was einen Boost-Takt von 1.325 MHz möglich gemacht hätte. Über die Entwicklung hinweg hat man die Anzahl der Voltage Paths auf über 1.700 erhöht. Damit konnte ein Boost-Takt von mindestens 1.733 MHz, wie er bei der GeForce GTX 1080 möglich ist, erreicht werden. Sicherlich wäre es möglich gewesen, die Anzahl der Voltage Paths weiter zu erhöhen, allerdings hätte dies in keinem Verhältnis zur weiteren Taktsteigerung gestanden.
Neben der GPU selbst sind bei der Strom- und Spannungsversorgung natürlich auch die Anforderungen an die weiteren daran beteiligten Komponenten gestiegen. So muss das GPU-Package ebenso gleichmäßig mit den notwendigen Spannungen versorgt werden. NVIDIA hat dazu das Board Channel Design optimiert, was vor allem das Layout des PCBs betrifft. Wieder einen Schritt näher an die GPU-Architektur selbst rückt man mit einem Redesign der GPU Circuit Architektur – also den spannungsversorgenden Komponenten, die sich direkt auf der GPU selbst befinden.

Eine neue Spannungsversorgung für mehr Leistung
Ebenso hohe Anforderungen werden an das PCB, das BGA des GPU-Package und das Package selbst gestellt, wenn es um die Übertragung der Signale an das PCI-Express-Interface oder den angebundenen GDDR5X-Speicher geht. Der Speicher spielt vor allem dann eine Rolle, wenn er wie in diesem Fall Frequenzen von bis zu 2.500 MHz erreicht. Sobald die Wellenlänge der Signale in der Größenordnung der Leitungslänge reicht ein vereinfachtes Modell aus ohmschen Widerstand, Leitungsquerschnitt, Leitfähigkeit und eben der Länge nicht mehr aus. Durch die auf jeder Leitung vorhandenen Kapazitäts- und Induktivitätsbeläge breiten sich die Signale maximal mit Lichtgeschwindigkeit aus.
Um bei den vorhandenen Laufzeiten überhaupt noch eine Signalintegrität gewährleisten zu können, muss die Modulation und Detektion der Signale extrem präzise sein. Um die Laufzeiten möglichst identisch zu halten sind die Speicherchips ohnehin schon relativ regelmäßig um die GPU herum platziert. Diese Methodik wird sich mit zukünftigen Speichergenerationen immer weiter verstärken und durch die Hersteller optimiert werden müssen.
