
Werbung
Die GPU Technology Conference ist typischerweise keine Veranstaltung, auf der NVIDIA neue GPU-Architekturen enthüllt. Vielmehr nutzt NVIDIA die GTC zur Aktualisierung der Roadmaps für GPUs sowie Tegra und gibt einen Ausblick auf neue Technologien. Dieses Mal aber ging NVIDIA einen anderen Weg und präsentierte die Tesla P100. Diese basiert auf einer neuen GPU, die wiederum auf der Pascal-Architektur beruht. Doch bevor es zur eigentlichen Produktpräsentation ging, nannte Jen-Hsun Huang auf der Bühne die Kosten für die Entwicklung der Pascal-Architektur und für die Tesla P100, die bei 2-3 Milliarden US-Dollar gelegen haben sollen. Natürlich nennt NVIDIA hier keine exakten Zahlen, um der Konkurrenz nicht allzu viele Hinweise zu geben. Solche Zahlen werden üblicherweise unter Verschluss gehalten.

Doch zunächst einmal zur Rechenleistung der Tesla P100: 5,3 TFLOPS bei FP64-Berechnungen, 10,6 TFLOPS bei FP32-Berechnungen und 21,2 TFLOPS bei FP16-Berechnungen – die letztgenannten sind vor allem für Deep-Learning-Netzwerke wichtig. Der P100, also die GPU selbst, besteht aus 15,3 Milliarden Transistoren und ist damit hinsichtlich der Transistoren doppelt so komplex, wie GM200 auf Basis der Maxwell-Architektur. Das komplette Modul, also die GPU zusammen mit dem Speicher und dem Interposer, kommt auf 150 Milliarden Transistoren. Auf dem Chip kommen 14 MB Shared Memory alleine für den Register-Cache zum Einsatz. Dieser Register erreichen über die komplette GPU hinweg eine Bandbreite von 80 TB/s. Hinzu kommen 4 MB an L2-Cache.
Während sich NVIDIA nicht zur Anzahl der Shadereinheiten äußert, wird zumindest die Speicherart und Größe erwähnt. So verwendet NVIDIA HBM der 2. Generation für die Tesla P100, die Größe liegt bei 16 GB. NVIDIA gibt an, dass sich die ersten Tesla-P100-Boards in der Produktion befinden und noch im 1. Quartal ausgeliefert werden sollen. Damit scheint Samsung die Massenproduktion des Speichers bereits deutlich stärker hochgefahren zu haben, als dies erwartet wurde. Jen-Hsun Huang erwähnte auf der Bühne, dass GPU und Speicher über mehr als 4.000 Verbindungen miteinander verbunden sind. Ein 4.096 Bit breites Speicherinterface dürfte damit auch keine Überraschung mehr sein. NVIDIA gibt eine Speicherbandbreite von 720 GB/s an. Die GPU selbst wird in 16 nm FinFET gefertigt, vermutlich von TSMC. Ebenfalls von TSMC stammt die Technologie, die GPU und Speicher auf dem Interposer unterbringt. CoWoS (Chip-on-Wafer-on-Substrate) ist eine Technik, die ebenfalls von TSMC stammt und damit kann NVIDIA die GPU weitestgehend dort fertigen lassen, während AMD auf andere Unternehmen angewiesen ist. In einem gesonderten Artikel sind wir darauf bereits genauer eingegangen.

In einer Tabelle haben wir die technischen Daten der Tesla P100 einmal gegen die bisherigen High-End-Consumer-Produkte von AMD und NVIDIA gestellt. Der Vergleich ist natürlich nicht ganz einfach, da es sich um unterschiedliche Produktkategorien handelt, dennoch sind auf besimmten Ebenen direkte Vergleiche möglich.
| Die technischen Daten der Tesla P100 im Überblick | |||
|---|---|---|---|
| Modell | NVIDIA Tesla P100 | AMD Radeon R9 Fury X | NVIDIA GeForce GTX 980 Ti |
| Straßenpreis | - | ab 615 Euro | ab 620 Euro |
| Homepage | www.nvidia.de | www.amd.de | www.nvidia.de |
| Technische Daten | |||
| GPU | P100 | Fiji XT | GM200 |
| Fertigung | 16 nm | 28 nm | 28 nm |
| Transistoren | 15,3 Milliarden | 8,9 Milliarden | 8 Milliarden |
| GPU-Takt (Base Clock) | 1.328 MHz | - | 1.000 MHz |
| GPU-Takt (Boost Clock) | 1.480 MHz | 1.050 MHz | 1.075 MHz |
| Speichertakt | 737 MHz | 500 MHz | 1.750 MHz |
| Speichertyp | HBM2 | HBM | GDDR5 |
| Speichergröße | 16 GB | 4 GB | 6 GB |
| Speicherinterface | 4.096 Bit | 4.096 Bit | 384 Bit |
| Speicherbandbreite | 720 GB/s | 512,0 GB/Sek. | 336,6 GB/s |
| DirectX-Version | 12 | 12 | 12 |
| Shadereinheiten | 3.584 | 4.096 | 2.816 |
| Textureinheiten | 224 | 256 | 176 |
| ROPs | - | 64 | 96 |
| Typische Boardpower | 300 W | 275 W | 250 W |
| SLI/CrossFire | - | CrossFire | SLI |
Bereits aus dem vergangenen Jahr sind Funktionen und Features wie die Mixed Precision Einheiten, NVLink und 3D Memory/HBM2 bekannt. Diese wollen wir an dieser Stelle noch einmal aufarbeiten.
[h3]Mixed Precision[/h3]

Mit dem Tegra X1 führt NVIDIA innerhalb des Maxwell-GPU-Parts des SoC den "Double Speed FP16"-Support ein. Wie die Fermi- und Kepler-Architektur zuvor auch, bietet Maxwell dedizierte FP32- und FP64-CUDA-Kerne. Dies ist auch beim Maxwell-Cluster auf dem Tegra X1 so. Allerdings spielen in diesem Segment FP16-Berechnungen eine wesentlich größere Rolle. NVIDIA hat also das Handling dieser FP16-Berechnungen geändert, um von den dedizierten FP32-Kernen profitieren zu können. Dazu werden FP16-Berechnungen zusammengelegt, damit sie auf FP32-Kernen ausgeführt werden können. Damit die FP16-Berechnungen zusammengelegt werden können, müssen sie allerdings die gleichen Operationen ausführen. Zum Beispiel können nur zwei Additionen oder zwei Multiplikationen zusammengeführt werden. FP16-Operationen sind für die Ausführung von Android ebenso entscheidend wie bei Spielen oder der Analyse von Foto- und Videodaten.
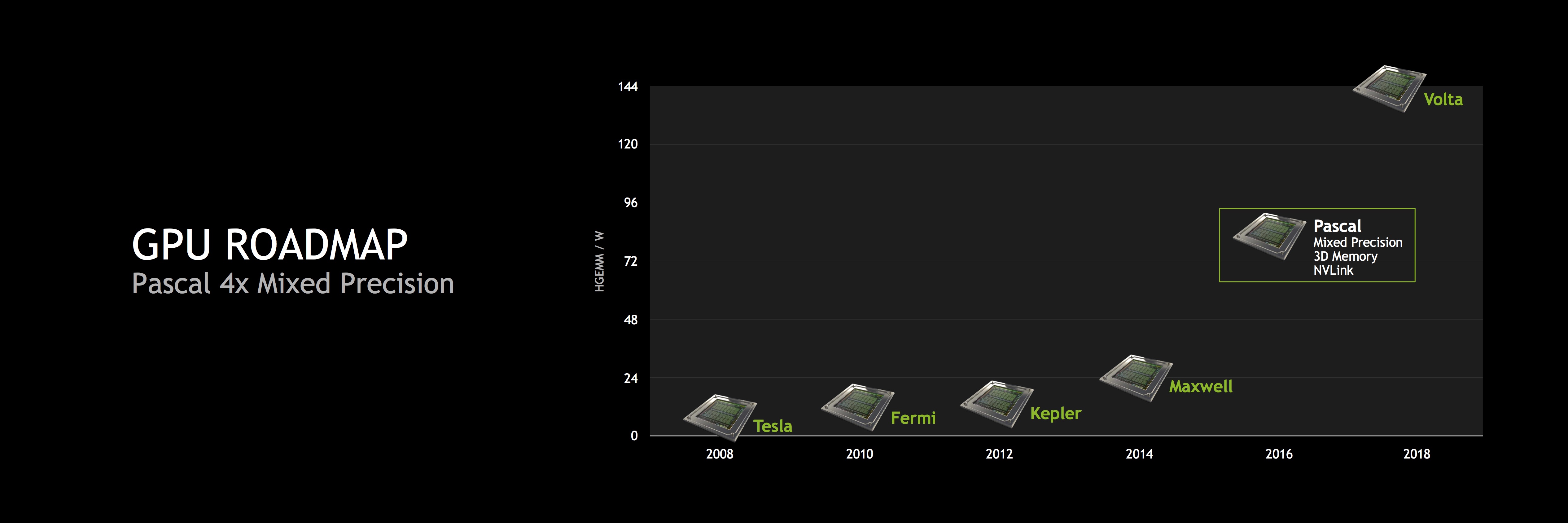
Warum ist das für Pascal interessant? Mit Pascal werden die Mixed Precision Einheiten großflächig in der GPU verwendet, um die unterschiedlichen Bedürfnisse abzudecken. Dabei handelt es sich genau um die Funktion, die den Shadereinheiten im Tegra X1 bereits heute ermöglicht wird. Die Überführung von Technologie der GeForce-GPUs in die Tegra-SoCs erfolgt nun also erstmals auch in der anderen Richtung - also von der Tegra-Hardware in eine kommende GPU-Architektur. Innerhalb von Tegra X1 spielen die zusammenfassbaren FP16-Operationen vor allem im Bereich der Bild- und Video-Analyse eine wichtige Rolle. Auch der Android Display Composer verwendet verstärkt FP16-Operationen, insofern macht ein Fokus auf diese Berechnungen für Tegra X1 Sinn. Warum aber implementiert NVIDIA eine solche Technik in Pascal? Bisher sehen die Pläne NVIDIAs für FP16 besonders eine Erhöhung der Compute-Performance vor. Deep-Learning-Netzwerke profitieren besonders von einer Leistungssteigerung in diesem Bereich. NVIDIA selbst spricht von einem Faktor vier gegenüber Maxwell. Ob auch Spieler davon profitieren können, bleibt abzuwarten.
[h3]NVLink[/h3]
NVLink ist ein wichtiger Bestandteil aktueller und zukünftiger HPC-Systeme mit NVIDIA-GPU. Eine Unterstützung von NVLink in IBM-Prozessoren ist angedacht und teilweise auch schon umgesetzt worden. Das Lizenzprogramm für NVLink läuft aber weiter und neben HP, die bereits Server mit NVLink anbieten, befindet sich NVIDIA weiterhin in Gesprächen mit zahlreichen Partnern.
3D, Stacked Memory oder High Bandwidth Memory öffnet den Flaschenhals zwischen GPU und Grafikspeicher, NVLink soll die Verbindung zwischen GPU und CPU sowie GPUs untereinander revolutionieren. Dazu sollte man sich zunächst einmal die Bandbreiten vor Augen führen, die aktuell per PCI-Express bereitgestellt werden. 16 PCI-Express-3.0-Lanes erreichen eine Bandbreite von 15,75 GB pro Sekunde bzw. 128 GT/s. NVIDIA hat bereits in die "Maxwell"-Architektur eine Speicherkomprimierung integriert, welche dem zunehmenden Bedarf an Speicherbandbreite entgegenkommen soll.
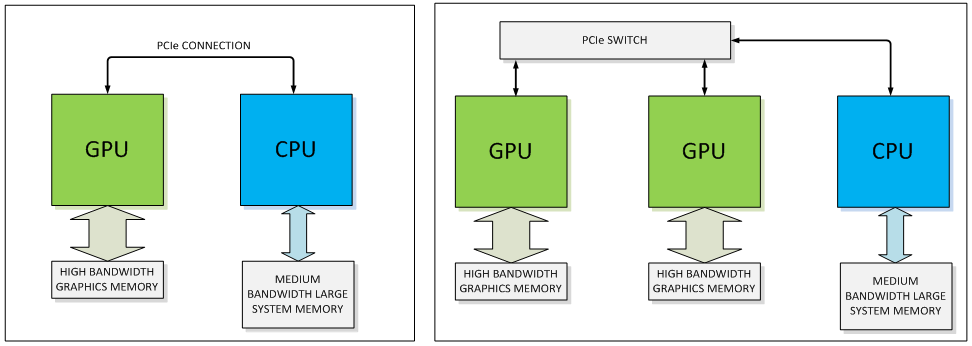
Laut NVIDIA soll NVLink fünf bis zwölf mal schneller sein. Die Bandbreite wird demzufolge zwischen 80 und 200 GB pro Sekunde liegen. Bis dahin werden wir vermutlich bereits PCI-Express 4.0 sehen, das die Bandbreite von PCI-Express 3.0 noch einmal verdoppelt und damit auf 31,51 GB pro Sekunde bzw. 256 GT/s kommt.
NVIDIA setzt für NVLink eine direkt Punkt-zu-Punkt-Verbindung ein. Diese besteht wiederum aus jeweils acht Lanes pro NVLink-Verbindung. Pascal wird zunächst einmal vier NVLinks anbieten können. Laut NVIDIA lässt sich deren Anzahl aber auch abhängig vom gewünschten Zielmarkt anpassen - allerdings wohl zunächst einmal nicht für Pascal sondern in Hinblick auf zukünftige GPUs. Die NVLink-Verbindungen können dabei flexibel zusammengefasst, um auch hier wieder dem jeweiligen Anwendungsfall gerecht zu werden. Denkbar ist beispielsweise eine einfache GPU-CPU-Verbindung, aber auch ein Netzwerk aus GPU-CPU- und GPU-GPU-Verbindungen.

Natürlich muss neben der GPU auch die CPU den Support von NVLink anbieten. Bisher hat nur IBM mit seinen PowerPC-Prozessoren einen Support von NVLink angekündigt. NVIDIA ist laut eigener Aussage aber auch mit Herstellern von ARM-Prozessoren in Gesprächen, um entsprechende Hardware für den Server-Bereich mit dem Release von Pascal anbieten zu können. Mit dem eigenen Projekt Denver hat man natürlich auch eine CPU-Architektur in der Pipeline, die mit einer Version des Tegra K1 auch schon implementiert wurde. Noch einmal sollte an dieser Stelle betont werden, dass NVLink zunächst einmal nur im professionellen Bereich eine Rolle spielen wird. Für den Desktop wird es eine Version des Pascal-Boards geben, das ohne NVLink und mit PCI-Express daherkommt. NVLink wird im professionellen Umfeld PCI-Express auch nicht vollständig ersetzen. Die bisher über das PCI-Express-Interface übertragenen Kontroll- und Konfigurations-Daten werden weiterhin auch dort verbleiben - NVLink wird sich dann nur um die für die GPU relevanten Daten kümmern.
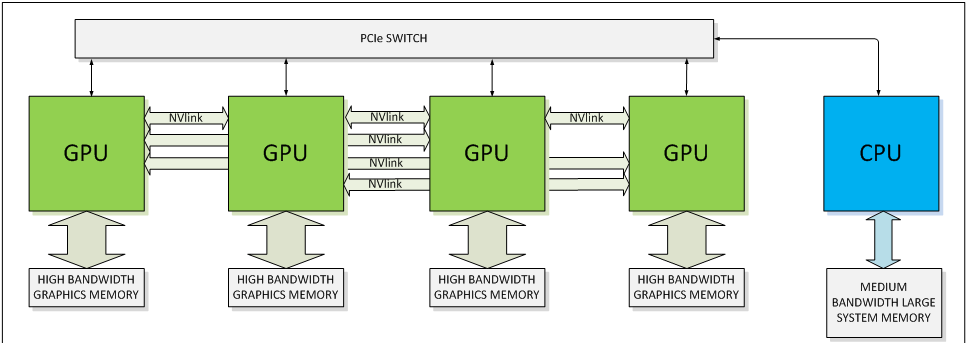
Soweit etwas Hintergrund zu NVLink in der Pascal-GPU. Derzeit hat NVIDIA noch keine konkreten Pläne, wie ein solches Pascal-Modul zu einem klassischen Desktop-PC mit seinen ATX-Normen passen soll. Wir sind gespannt, ob es dazu in nächster Zeit noch weitere Informationen gibt oder ob NVIDIA am Ende wieder auf das klassische Design setzt und das Pascal-Modul nur ein Schritt in der Entwicklung dorthin war.
[h3]HBM2[/h3]
Während Mixed Precision und NVLink für den Endkunden zunächst einmal keine große Rolle Spielen werden, wird der neue Speicher wohl die interessanteste technische Änderung der neuen GPU-Generation von NVIDIA. Die deutlich größere Speicherbandbreite spielt einen entscheidenden Faktor beim Zusammenspiel von GPU und Speicher. AMD machte im vergangenen Jahr mit den Fiji-GPUs den ersten Schritt. Etwas überraschend hat NVIDIA nun angekündigt, dass die Tesla P100 bereits im aktuellen Quartal mit HBM2 ausgeliefert wird.

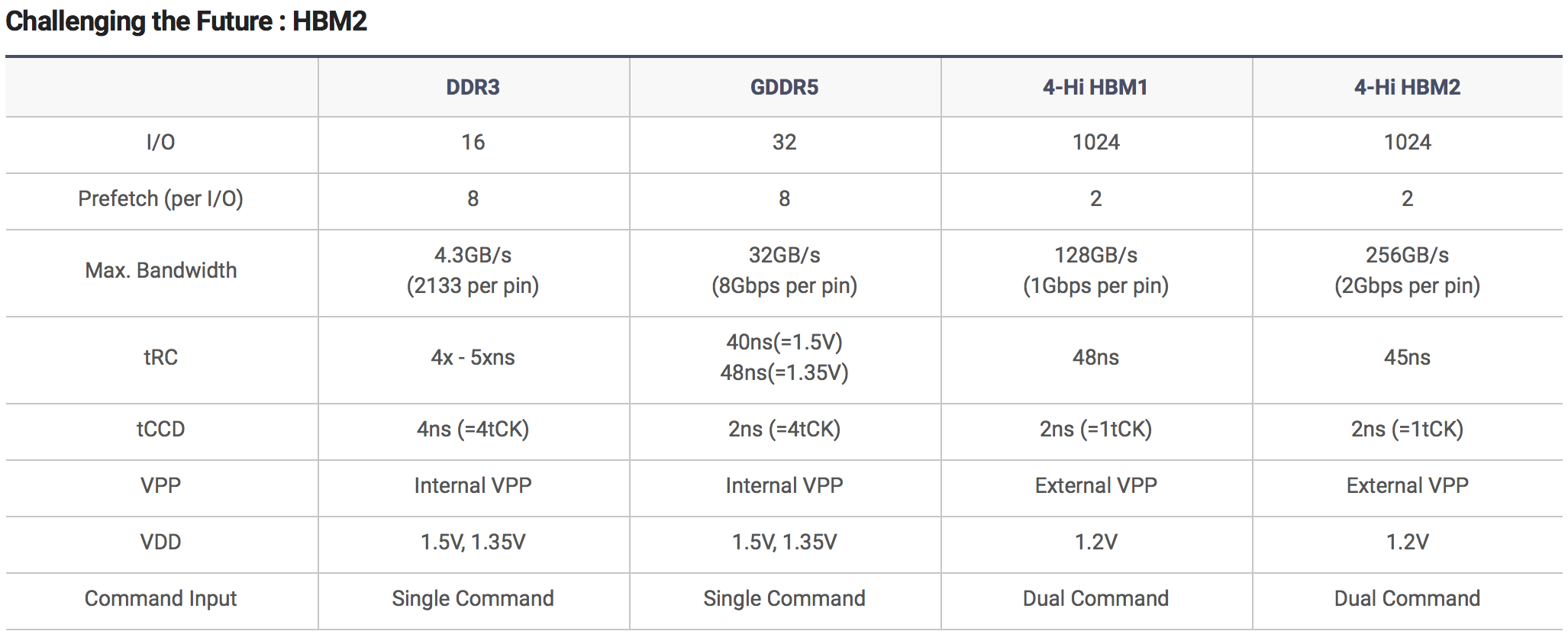
Der "JESD235 High Bandwidth Memory (HBM) DRAM Standard" getaufte Standard beschreibt HBM2 mit 2, 4 oder 8 Hi-Stacks und damit wird die Kapazität pro HBM2-Chip zwischen 1 und 8 GB betragen. Da bisher bei den Fury-GPUs vier dieser Chips zum Einsatz kamen und auch für die kommenden Vega- und Pascal-GPUs der Einsatz von vier Chips erwartet wird, könnte die Speicherkapazität dieser neuen Grafikkarten bis zu 32 GB betragen – bei der Tesla P100 sind es nun 16 GB.
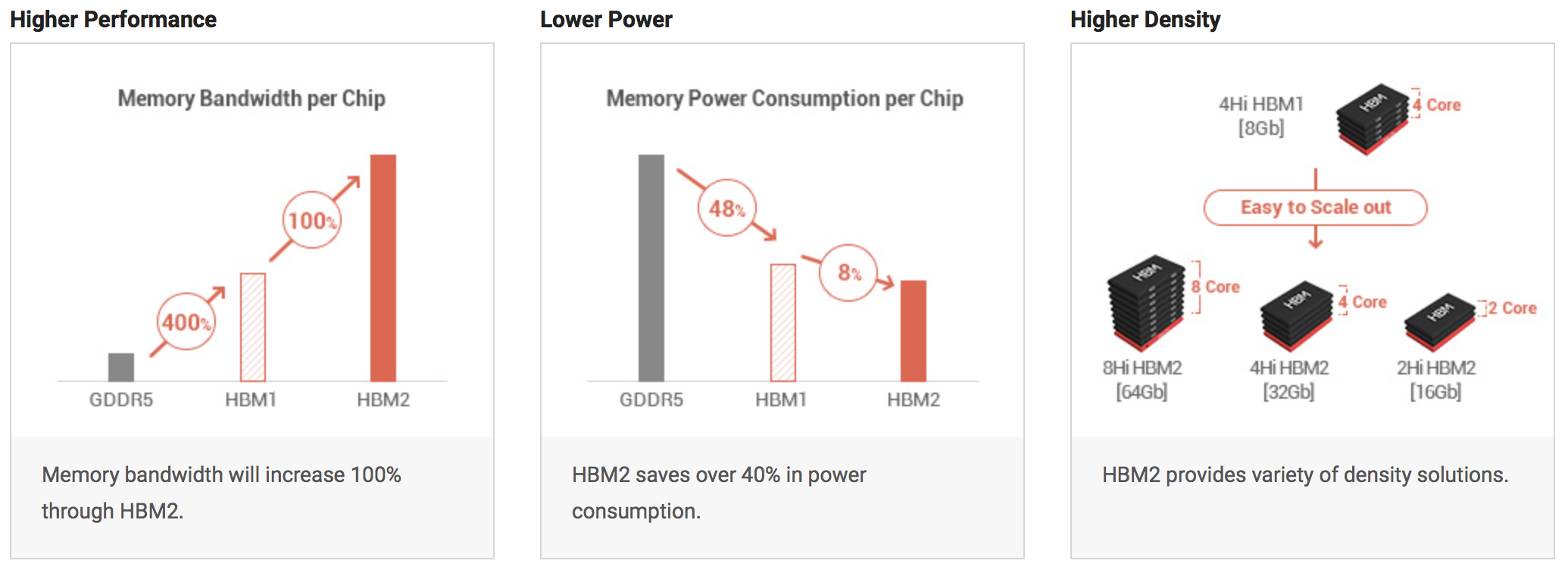
HBM2 ermöglicht den Einsatz von 2-Hi-Stacks mit einer Kapazität von 1 GBit pro Stack, was eine Gesamtkapazität von nur 1 GB möglich macht (2x 1.024 Bit x 4 Chips) - sozusagen den Mindestausbau beschreibt. Neben der Speicherkapazität spielt aber auch die Speicherbandbreite eine wichtige Rolle und auch diese wird mit HBM2 weiter verbessert. Dazu wird der Takt von 500 auf 1.000 MHz angehoben. Bei einem weiteren 1.024 Bit breiten Speicherinterface pro Stapel bedeutet dies eine schlichte Verdopplung der Speicherbandbreite – während die Fiji-GPUs demnach noch mit HBM bei 512 GB/s arbeiten, können zukünftige GPUs auf 1.024 GB/s kommen.
Zusammenfassend kann festgehalten werden, dass HBM2 den Grafikkartenherstellern eine doppelt so hohe Speicherbandbreite bei bis zu achtfacher Speicherkapazität zur Verfügung stellt. Die Spannung verbleibt bei 1,2 V. AMD hat bereits Erfahrungen mit HBM sowie der Unterbringung auf einem Interposer gesammelt. Aus technischer Sicht sind die verwendeten Technologien eine Herausforderung für die Hersteller, aber auch sehr interessant, so dass wir uns dem Thema in einem gesonderten Artikel angenommen haben.
Wir werden diesen Artikel in den kommenden Minuten oder Stunden noch weiter ausbauen. Die Keynote auf der GTC läuft noch und eine Fragestunde nach der Keynote könnte weitere Erkenntnisse bringen.
