
NVLink
-
Noch ohne NVLink: Intel Xeon 6 dient weiterhin als x86-Host für DGX Rubin NVL8
 Den Zug bei den KI-Beschleunigern hat Intel vollends verpasst, aber immerhin partizipiert man mit seinen x86-Prozessoren in der Form, als dass einige der Xeon-Modelle als Host-CPU zum Einsatz kommen. Dies ist schon bei NVIDIAs DGX B300 der Fall und wird in der nächsten Generation mit den DGX Rubin NVL8 fortgesetzt. Konkret zum Einsatz kommen weiterhin zwei Intel Xeon 6776P mit jeweils 64 Kernen. Auf zwei Prozessoren als Host kommen... [mehr]
Den Zug bei den KI-Beschleunigern hat Intel vollends verpasst, aber immerhin partizipiert man mit seinen x86-Prozessoren in der Form, als dass einige der Xeon-Modelle als Host-CPU zum Einsatz kommen. Dies ist schon bei NVIDIAs DGX B300 der Fall und wird in der nächsten Generation mit den DGX Rubin NVL8 fortgesetzt. Konkret zum Einsatz kommen weiterhin zwei Intel Xeon 6776P mit jeweils 64 Kernen. Auf zwei Prozessoren als Host kommen... [mehr] -
RISC-V-Kerne im KI-Rechenzentrum: Auch SiFive will NVIDIAs NVLink Fusion nutzen
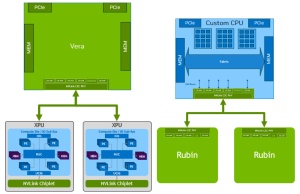 ARM, Qualcomm, Intel und Fujitsu haben bereits angekündigt, dass sie NVIDIAs NVLink Fusion für zukünftige CPU-Designs nutzen werden. Nun verkündet auch SiFive, dass man am entsprechenden Programm teilnehmen wird. Damit sind auch alle drei wichtigen CPU-Architekturen vertreten: x86, ARM und nun eben RISC-V. Bei SiFive hat man keinerlei konkrete Ankündigung, welches CPU-Design für die Integration von NVLink vorgesehen ist. Aber derart... [mehr]
ARM, Qualcomm, Intel und Fujitsu haben bereits angekündigt, dass sie NVIDIAs NVLink Fusion für zukünftige CPU-Designs nutzen werden. Nun verkündet auch SiFive, dass man am entsprechenden Programm teilnehmen wird. Damit sind auch alle drei wichtigen CPU-Architekturen vertreten: x86, ARM und nun eben RISC-V. Bei SiFive hat man keinerlei konkrete Ankündigung, welches CPU-Design für die Integration von NVLink vorgesehen ist. Aber derart... [mehr] -
RTX-GPU-Chiplets und Custom-Xeons: NVIDIA und Intel arbeiten zukünftig zusammen
 Intel und NVIDIA haben einerseits eine Kooperation angekündigt und auf der anderen Seite investiert NVIDIA in den in einigen Bereichen als Konkurrent aufgestellten ehemaligen blauen Chipriesen. Dazu kauft der grüne KI-Riese Intel-Aktien im Wert von 5 Milliarden US-Dollar. Es dürfte sich dabei auch um eine strategische Investition handeln, die NVIDIA in die Situation versetzt, eine gewisse Kontrolle über die Host-Hardware in Form der... [mehr]
Intel und NVIDIA haben einerseits eine Kooperation angekündigt und auf der anderen Seite investiert NVIDIA in den in einigen Bereichen als Konkurrent aufgestellten ehemaligen blauen Chipriesen. Dazu kauft der grüne KI-Riese Intel-Aktien im Wert von 5 Milliarden US-Dollar. Es dürfte sich dabei auch um eine strategische Investition handeln, die NVIDIA in die Situation versetzt, eine gewisse Kontrolle über die Host-Hardware in Form der... [mehr] -
Hot Chips 2025: Weitere Details zu NVLink Fusion
 Bereits zur Computex in diesem Jahr kündigte NVIDIA (erneut) an, die eigene Interconnect-Technologie NVLink auch anderen Chipherstellern zur Verfügung zu stellen. Auf der Hot-Chips-Konferenz in diesem Jahr will NVIDIA einige technische Details verraten und hat in einem Vorab-Briefing auch schon einen kleinen Einblick gegeben. NVIDIA verbindet seine eigenen CPUs und GPUs über den NVLink-Interconnect, der in der aktuell für die... [mehr]
Bereits zur Computex in diesem Jahr kündigte NVIDIA (erneut) an, die eigene Interconnect-Technologie NVLink auch anderen Chipherstellern zur Verfügung zu stellen. Auf der Hot-Chips-Konferenz in diesem Jahr will NVIDIA einige technische Details verraten und hat in einem Vorab-Briefing auch schon einen kleinen Einblick gegeben. NVIDIA verbindet seine eigenen CPUs und GPUs über den NVLink-Interconnect, der in der aktuell für die... [mehr] -
UALink 1.0: AMD stellt sich mit offener NVLink-Alternative auf
 Eines der größten Probleme für AMDs Infrastruktur ist, dass bisher nur acht Beschleuniger per Infinity Fabric direkt miteinander verbunden werden können. Während NVIDIA per NVLink inzwischen 72 Blackwell-Packages mit 900 GB/s direkt miteinander verbinden kann, kommt AMD in der vierten Infinity-Fabric-Generation auf 153,6 GB/s. Über den Node mit acht Beschleunigern hinaus muss AMD auf per PCI-Express angebundene Ethernet-Verbindungen... [mehr]
Eines der größten Probleme für AMDs Infrastruktur ist, dass bisher nur acht Beschleuniger per Infinity Fabric direkt miteinander verbunden werden können. Während NVIDIA per NVLink inzwischen 72 Blackwell-Packages mit 900 GB/s direkt miteinander verbinden kann, kommt AMD in der vierten Infinity-Fabric-Generation auf 153,6 GB/s. Über den Node mit acht Beschleunigern hinaus muss AMD auf per PCI-Express angebundene Ethernet-Verbindungen... [mehr] -
NVLink Fusion: NVIDIA öffnet NVLink-C2C für Custom-CPUs und GPUs
 Neben dem durch die Rahmenbedingungen fragwürden Marktstart der GeForce RTX 5060 hat NVIDIA zur Computex auch eine Ankündigung aus dem Datacenter-Segment. NVIDIA verbindet seine eigenen CPUs und GPUs über den NVLink-Interconnect, der in der aktuell für die Blackwell-GPUs verwendeten 5. Generation auf 50 GB/s pro NVLink-Lane kommt und somit bei 18 insgesamt vorhandenen NVLink-Lanes in der Umsetzung bidirektional 1.800 GB/s erreicht. Bis zu 72... [mehr]
Neben dem durch die Rahmenbedingungen fragwürden Marktstart der GeForce RTX 5060 hat NVIDIA zur Computex auch eine Ankündigung aus dem Datacenter-Segment. NVIDIA verbindet seine eigenen CPUs und GPUs über den NVLink-Interconnect, der in der aktuell für die Blackwell-GPUs verwendeten 5. Generation auf 50 GB/s pro NVLink-Lane kommt und somit bei 18 insgesamt vorhandenen NVLink-Lanes in der Umsetzung bidirektional 1.800 GB/s erreicht. Bis zu 72... [mehr] -
Schon gelöst: GB200 soll Probleme mit dem Spine-Interconnect gehabt haben
 Bereits häufiger war zusammen mit NVIDIAs GB200-Systemen von Problemen die Rede und nun kommt ein weiterer Bericht hinzu, dessen Legitimität jedoch stark in Frage zu stellen ist, als dies bei den anderen Meldungen der Fall war. Der in Taiwan ansässige Analyst Dan Nystedt berichtet via X, dass Microsoft 40 % seiner Bestellungen an GB200-KI-Servern storniert habe, da diese später als erwartet ausgeliefert würden. Die Auslieferung... [mehr]
Bereits häufiger war zusammen mit NVIDIAs GB200-Systemen von Problemen die Rede und nun kommt ein weiterer Bericht hinzu, dessen Legitimität jedoch stark in Frage zu stellen ist, als dies bei den anderen Meldungen der Fall war. Der in Taiwan ansässige Analyst Dan Nystedt berichtet via X, dass Microsoft 40 % seiner Bestellungen an GB200-KI-Servern storniert habe, da diese später als erwartet ausgeliefert würden. Die Auslieferung... [mehr] -
Zukünftige AI-Hardware: Blackwell und Blackwell NVLink Switch im Einsatz
 Zur Hot-Chips-Konferenz 2024 spricht NVIDIA über einige weitere Details seiner Blackwell-Generation der KI-Beschleuniger, bzw. die dazugehörige Netzwerk-Hardware. Zunächst einmal gab es in den vergangenen Monaten immer wieder Gerüchte zu einer Verschiebung von Blackwell im Datacenter und tatsächlich musste NVIDIA eine neue Revision des Chips, bzw. Package auflegen, was einen Neustart in der Fertigung bei TSMC nach sich gezogen hat. Davon... [mehr]
Zur Hot-Chips-Konferenz 2024 spricht NVIDIA über einige weitere Details seiner Blackwell-Generation der KI-Beschleuniger, bzw. die dazugehörige Netzwerk-Hardware. Zunächst einmal gab es in den vergangenen Monaten immer wieder Gerüchte zu einer Verschiebung von Blackwell im Datacenter und tatsächlich musste NVIDIA eine neue Revision des Chips, bzw. Package auflegen, was einen Neustart in der Fertigung bei TSMC nach sich gezogen hat. Davon... [mehr] -
Wichtige KI-Infrastruktur: NVIDIA stellt neue NVLink-Generation und Switches vor
 Bereits recht früh hatte NVIDIA verstanden, dass ein einzelner leistungsstarker Chip auch darauf angewiesen ist, seine Daten möglichst schnell austauschen zu können und im HPC- und AI-Bereich ist eine gute Skalierung der Systeme über mehreren tausend Beschleuniger und Knoten darauf angewiesen, dass eine entsprechend schnelle Verbindung zwischen den Knoten und Beschleunigern besteht. Die aktuell vierte Generation von NVLink kommt auf eine... [mehr]
Bereits recht früh hatte NVIDIA verstanden, dass ein einzelner leistungsstarker Chip auch darauf angewiesen ist, seine Daten möglichst schnell austauschen zu können und im HPC- und AI-Bereich ist eine gute Skalierung der Systeme über mehreren tausend Beschleuniger und Knoten darauf angewiesen, dass eine entsprechend schnelle Verbindung zwischen den Knoten und Beschleunigern besteht. Die aktuell vierte Generation von NVLink kommt auf eine... [mehr] -
GH200 NVL32: AWS und NVIDIA bauen KI-Supercomputer
 Neben der Ankündigung zweier neuer Chips in Form des Graviton4 und Trainium2 haben die Amazon Web Services (AWS) und NVIDIA eine Zusammenarbeit zum Aufbau eines KI-Supercomputers in der Cloud angekündigt. Das Ceiba getaufte System wird 16.384 GH200-Beschleuniger verwenden und wird damit zu den größten System mit dieser Hardware gehören. Erst vor wenigen Wochen kündigte NVIDIA zur Supercomputing 2023 an, dass man 2024 zahlreiche Systeme mit dem... [mehr]
Neben der Ankündigung zweier neuer Chips in Form des Graviton4 und Trainium2 haben die Amazon Web Services (AWS) und NVIDIA eine Zusammenarbeit zum Aufbau eines KI-Supercomputers in der Cloud angekündigt. Das Ceiba getaufte System wird 16.384 GH200-Beschleuniger verwenden und wird damit zu den größten System mit dieser Hardware gehören. Erst vor wenigen Wochen kündigte NVIDIA zur Supercomputing 2023 an, dass man 2024 zahlreiche Systeme mit dem... [mehr] -
Grace: NVIDIA kombiniert ARM-Prozessor, GPU und schnellen Interconnect
 Auf der GPU Technology Conference stellt NVIDIA mit Grace einen eigenen HPC-ARM-Prozessor vor, welcher in zukünftigen Supercomputern zum Einsatz kommen soll. Benannt ist der Prozessor nach Grace Hopper. Hopper war eine Informatikerin und Computerpionierin, die sich vor allem mit ihrer Arbeit, Computerprogramme in einer verständlichen Sprache zu verfassen, einen Namen gemacht hat. Der Grace-Prozessor soll als Basis eine kommenden... [mehr]
Auf der GPU Technology Conference stellt NVIDIA mit Grace einen eigenen HPC-ARM-Prozessor vor, welcher in zukünftigen Supercomputern zum Einsatz kommen soll. Benannt ist der Prozessor nach Grace Hopper. Hopper war eine Informatikerin und Computerpionierin, die sich vor allem mit ihrer Arbeit, Computerprogramme in einer verständlichen Sprache zu verfassen, einen Namen gemacht hat. Der Grace-Prozessor soll als Basis eine kommenden... [mehr] -
Ampere-Architektur Deep-Dive: GA100 ohne RT-Kerne und Details zum neuen NVSwitch
In einem sogenannten Deep Dive hat Jonah Alben, Senior Vice President des GPU-Engineering bei NVIDIA einige weitere Fragen und Details zur Ampere-Architektur beantwortet. Alle wichtigen Details zur Ampere-Architektur haben wir uns bereits angeschaut. Darüber hinaus haben wir uns bereits in einer Analyse damit beschäftigt, wie viel GeForce in der GA100-GPU steckt. Wer sich neue Erkenntnisse zu einer möglichen nächsten Generation der... [mehr] -
GA100: 7 nm, 54 Milliarden Transistoren – NVIDIA präsentiert die Ampere-Architektur
NVIDIA hat auf der virtuellen Keynote der GPU Technology Conference die Katze aus dem Sack gelassen und die Ampere-Architektur vorgestellt. Noch kennen wir nicht alle Details, aber wir kennen einige Eckdaten der neu vorgestellten Produkte. Nach der Vorstellung der Volta-Architektur vor drei Jahren, stellt NVIDIA nun den Nachfolger vor. Die Ampere-Architektur wurde im Hinblick auf drei Ziele entwickelt: Die Leistung sollte signifikant... [mehr] -
Supermicro C9Z390-PGW: Sockel 1151 mit PCIe-Bridge oder ohne?
Auch wenn Multi-GPU-Lösungen im Endkunden-Bereich immer weiter in den Hintergrund rücken, so ist der ein oder andere noch immer bereit, sich ein entsprechendes System zusammenzustellen. Dabei stellt sich die Frage nach dem richtigen Unterbau und hier sind für viele die zur Verfügung stehenden PCI-Express-Lanes entscheidend. Wir haben uns einmal angeschaut, wie sich dies beim Sockel LGA1151 darstellt und ob ein Supermicro C9Z390-PGW mit... [mehr] -
Die ersten Custom-NVLink-Bridges setzen auf RGB (Update)
Mit den neuen Karten der GeForce-RTX-Generation führt NVIDIA auch eine neue Multi-GPU-Technik ein, denn als erste GeForce-Modelle unterstützen diese NVLink. Mit der Verwendung von NVLink erhöht NVIDIA die zur Verfügung stehende Bandbreit. Die SLI-Brücke der ersten Generation kommt auf 1 GB/s, die darauf folgenden SLI-HB-Brücken erreichten 4 GB/s und machten ein SLI mit 4K-Auflösung mit mehr als 60 Hz möglich. Ein NVLink der... [mehr] -
NVIDIA beschleunigt den GPU-Interconnect und verdoppelt den HBM2-Speicher
In diesem Jahr scheint sich NVIDIA auf der GPU Technology Conference auf einen Ausbau der bestehenden Produkte und Technologien zu konzentrieren. So präsentiert man eine Quadro GV100 mit 32 GB HBM2 und auch die Tesla V100 kann ab sofort mit der doppelten Speicherkapazität bestückt werden. Um diese schnelle GPU-Beschleuniger besser einsetzen zu können, muss aber nicht nur die einzelne Hardware schneller werden, sondern auch die... [mehr] -
Microsoft kündigt Zusammenarbeit mit NVIDIA und AMD für Server an (Update)
Microsoft, AMD und NVIDIA – alle drei Unternehmen haben eine enge Zusammenarbeit im Cloud-Computing-Bereich angekündigt. Dabei verfolgen die einzelnen Unternehmen unterschiedliche Ansätze, um ihre Ziele zu verfolgen. Während Microsoft seine Position in diesem Bereich als Plattformanbieter festigen möchte, setzt NVIDIA voll auf das Wachstum mittels starker HPC-Hardware. AMD hingegen verfolgt einen offenen Ansatz für die eigene Hardware-Plattform... [mehr] -
IBM koppelt POWER8-CPUs mit vier Tesla-P100-GPUs via NVLink
Schlagwort hin oder her – Deep Learning und erste Ansätze zur AI spielen bereits eine wichtige Rolle bei der Benutzung vieler Services im Internet und die Abhängigkeiten von diesen Technologien werden in Zukunft immer größer werden. NVIDIA hat die eigenen GPUs, zumindest im professionellen Bereich, genau auf solche Anwendungen in ausgerichtet und präsentierte im Frühjahr den DGX-1, einen Supercomputer mit Tesla-P100-GPU-Beschleuniger. Wie der... [mehr] -
IBM POWER9: 24 Kerne, 120 MB L3-Cache und NVLink 2.0
Auch IBM nutzt die Hot Chips 28, um auf neue und zukünftige Produkte und Entwicklungen aufmerksam zu machen. Die Kollegen von Computerbase sind vor Ort und haben neben der Präsentation auch der dazugehörigen Präsentation durch IBM beigewohnt. IBM lenkte die Aufmerksam darin auf die zukünftige Prozessor-Architektur POWER9, die ab Mitte 2017 zahlreiche Server befeuern soll. Hauptmerkmale der POWER9-Prozessoren sind die Anzahl von 24 Kernen, die... [mehr] -
NVIDIA veröffentlicht Die-Shot zur GP100-GPU
Bei der Präsentation neuer Hardware und vor allem neuer Chips durch Hersteller wie AMD, NVIDIA oder Intel ist in den vergangenen Jahren vor allem eines auffällig: Nicht immer reden die Hersteller gerne über jedes Detail der Entwicklung und ungern wird Journalisten oder der Konkurrenz die Möglichkeit geboten, sich diese Details selbst zu erarbeiten. So wurden die beliebten Die-Shots von CPUs und GPUs in jüngster Vergangenheit lieber gegen ein... [mehr]
