
Werbung
Mit der heutigen Vorstellung der 3. Xeon-Scalable-Generation alias Ice Lake-SP lässt Intel auch im Serversegment das Zeitalter der Skylake-Architektur hinter sich. Diesen Schritt machte Intel mit dem Wechsel auf Rocket Lake-S auf dem Desktop erst kürzlich, im mobilen Segment sind zumindest die sparsamen Chips bereis seit mehr als einem Jahr auf einer komplett neuen Mikroarchitektur. Ice Lake-SP beschreibt zugleich die Probleme, die Intel mit der Fertigung in 10 nm hatte und noch immer hat, denn die 3. Xeon-Scalable-Generation kommt reichlich spät und wird auch bald schon einen Nachfolger sehen. Intel nutzt diese Generation für einen Plattformwechsel und eine teilweise Neuausrichtung. Wir schauen uns nun die Details zu Ice Lake-SP an.
Die Ice-Lake-Generation sollte ein plattformübergreifender Wechsel sein. Notebook, Desktop und Server sollten bereits 2017 auf die neue Architektur wechseln. Doch Intel hatte große Probleme mit der Einführung der Fertigung in 10 nm und komplett überwunden sind diese noch immer nicht. Die Auswirkungen für Intel als Integrated Device Manufacturer (IDM), der die Entwicklung der Chips und die Fertigung unter einem Dach ausführt, sind enorm. Allerdings sieht Intel im IDM-Konzept nun wieder Chancen und richtet den Konzern mit IDM 2.0 in dieser Hinsicht neu aus. Bis 2023/24 will Intel wieder eine Vorreiterrolle einnehmen. Mit der Fertigung in 7 nm will man wieder auf Augenhöhe mit den anderen Halbleiterherstellern sein und die mehrjährigen Probleme, die sich kaum besser als in den Rocket-Lake-Prozessoren ausdrücken lassen, überwunden haben.

Aber auch wenn es Ice Lake-H für Notebooks mit mehr als vier Kernen oder Ice Lake-S für den Desktop nie gegeben hat, so hielt Intel dennoch an den Plänen zu Xeon-Prozessoren auf Basis von Ice Lake fest. Bereits im vierten Quartal 2020 hat man die ersten Prozessoren an Kunden ausgeliefert, inzwischen sollen es bereits 200.000 sein. Heute fällt der offizielle Startschuss.
Neue Mikrocode-Architektur: Sunny Cove
Die Sunny-Cove-Architektur bedeutet für Intel den ersten Wechsel in den grundlegenden Strukturen einer CPU-Architektur seit Skylake aus dem Jahre 2015. Sechs Jahre hat Intel nun also kleinere Verbesserungen in Skylake einfließen lassen und bei aller Kritik daran hat Intel es dennoch geschafft, die Leistung im Vergleich zur ersten Generation der Prozessoren auf Basis der Skylake-Architektur bis zu den bis vor wenigen Wochen aktuellen Comet-Lake-Refresh-Prozessoren deutlich zu steigern. Dies hängt außerdem mit den Verbesserungen der Fertigungstechnologien zusammen, denn auch wenn es Skylake auf 10 nm nur im homöopathischen Dosen in Form von Canon Lake gegeben hat, so sind die Optimierungen durch 14nm+, 14nm++ und 14nm+++ signifikant. Rocket Lake-S erreicht 5,3 GHz auf einzelnen Kernen, bis zu 5,1 GHz sind es auf allen acht Kernen.
Doch Sunny Cove bringt nun den Wechsel auf eine völlig neue Architektur, die allerdings nun auch schon zwei Jahre alt ist. Intel nimmt ein paar Anpassungen vor, die für die Xeon-Version spezifisch sind.

Intel führt mit Sunny Cove eine 5-Wide-Out-of-Order-Architektur-Pipeline ein. Hier gibt es nun vier Unified Reservation Station (RS), was es Intel ermöglicht, die Instruktionen paralleler einfließen zu lassen, als bei Skylake. Womöglich um den Spectre-Mitigierungen entgegen zu wirken, hat Intel der AGU (Address Generation Unit) vier feste Ports zugewiesen. Jeweils zwei AGUs wird eine Load/Store-Unit zugewiesen. Für VEC- und INT-Berechnungen gibt es nun weitere Recheneinheiten in den jeweiligen Ports. All diese Maßnahmen sollen zur Beschleunigung der Architektur beitragen.
Das Front-end bekommt eine höhere Kapazität und die Sprungvorhersagen sollen zudem optimiert worden sein. Die eigentlichen Recheneinheiten sind mit Ice Lake in zwei Dimensionen (Pipeline-Tiefe) und der Breite vergrößert worden, können damit mehr Befehle aufnehmen und weitere Befehlssätze ausführen.
Intel hat zu diesem Zweck die Buffer und Caches im Vergleich zu Cascade Lake vergrößert. Diese können mehr Einträge aufnehmen und die dazugehörigen Load/Store-Einheiten wurden in ihrer Anzahl deutlich erweitert. Eine Änderung für Ice Lake-SP gibt es im Vergleich zu bisherigen Consumer-Version: Der L2-Cache pro Kern wächst von 512 KB pro Kern auf 1,25 MB pro Kern an. Für Cascade Lake belief sich die Kapazität noch auf 1 MB pro Kern.

Weiterhin wird Sunny Cove neue ISA-Befehlssätze unterstützen. Dazu gehören Vector-AES, verschiedene SHA-Erweiterungen und vieles mehr – allesamt auf Basis von AVX512. Bei den beiden erstgenannten handelt es sich um Algorithmen zur Hardwarebeschleunigung von Ver- und Entschlüsselungen. Generell soll der Fokus auf der Beschleunigung von Krypthografie-Algorithmen liegen, was wiederum die von Intel angesprochenen Optimierungen bei den speziellen Anwendungen betrifft. Das Leistungsplus gegenüber den Cascade-Lake-Prozessoren ist durchaus beachtlich.

Neben der Verwendung von bis zu 40 Sunny-Cove-Kernen betrifft eine wichtige Neuerung der Ice-Lake-SP-Prozessoren das Speicherinterface sowie die Reduzierung der Latenzen im L3-Cache und Arbeitsspeicher.
Im Vergleich zu den aktuellen Xeon-Prozessoren erhöht Intel die Anzahl der Speicherkanäle von sechs auf acht. Pro Speicherkanal können zwei Module verwendet werden. Bei der Geschwindigkeit geht Intel von DDR4-2933 auf DDR4-3200 – zumindest für die schnelleren Xeon-Modelle. Zum Vergleich: Zwar unterstützt auch AMD bei den EPYC-Prozessoren DDR4-3200, allerdings nur für ein Modul pro Speicherkanal. Gesteigerte Speicherbandbreite bei gleichzeitig geringeren Latenzen sollen das Geheimnis des neuen Speichercontrollers sein.
Per Ultra Path Interconnect (UPI) kommunizieren mehrere Xeon-Prozessoren in einem Multi-Socket-System miteinander. Intel sieht drei UPI-Links vor, die jeweils 11,2 GT/s erreichen können. Bisher waren hier 9,6, bzw. 10,4 GT/s möglich. Intel hat die Anbindung mehrerer Prozessoren also leicht beschleunigen können. Ein weiterer wichtiger Faktor ist sicherlich die Unterstützung von PCI-Express 4.0 - mehr als zwei Jahre nachdem AMD mit der zweiten EPYC-Generation auf PCI-Express 4.0 wechselte und damit die Möglichkeit bot, viel mehr externe Hardware deutlich schneller anzubinden. Mit 64 PCI-Express-Lanes bietet Intel selbst in der Ice-Lake-Generation nur halb so viele wie AMD. Ein Dual-Socket-System kommt immerhin auf 128 Lanes, da Intel den UPI als Interconnect zwischen den Sockeln verwendet. Bei AMD sind es im 2S-Betrieb nur 192, da 64 Lanes für die Kommunikation mit anderen Sockeln verwendet werden.

In Zahlen ausgedrückt verzeichnet Intel für die den L1-Cache geringfügig höhere Latenzen durch mehr Taktzyklen, die für einen Hit durchlaufen werden müssen und auch im L2 sind die Verbesserungen gegenüber Cascade Lake nicht vorhanden und AMD geringfügig im Vorteil. Beim L3-Cache muss man etwas genauer hinschauen und unterscheiden, ob die Daten bei den EPYC-Prozessoren im lokalen L3-Cache des CCDs liegen, oder auf einem anderen CCD. Lokal liegt die Latenz bei 13,4 ns, bei Intel sind es 21,7 ns. Müssen die Daten jedoch von einem anderen CCD erst übertragen werden, ist die Latenz mit 112 ns bei AMD deutlich höher. Hier zeigt sich eben der Unterschied zwischen einem monolithischen und einem Chiplet-Design. Man muss allerdings sagen, dass AMD einen bis zu 256 MB großen L3-Cache anzubieten hat, während es bei Intel nur 38,5 MB sind.
Ein weiterer Punkt bei den Latenzen ist der Zugriff in einem Multi-Sockel-System auf den L3-Cache eines entfernten Sockels. Diese liegen bei Intel nun bei 118 ns (Cascade Lake: 180 ns) und sind im Vergleich zu AMDs EPYC-Plattform mit 209 ns ebenfalls deutlich geringer.

Auch bei den Latenzen zum Arbeitsspeicher sieht sich Intel mit 85 und 139 ns gegenüber 96 zu 191 ns besser aufgestellt. Zudem wird - wie eben schon erwähnt - DDR4-3200 für zwei DIMMs pro Speicherkanal unterstützt, während dies bei AMDs EPYC-Prozessoren nur für ein Modul pro Speicherkanal möglich ist.
Bei der maximalen Speicherkapazität pro Sockel geben sich AMD und Intel mit Ice Lake-SP nichts mehr (beide können 4 TB ansprechen), allerdings kann bei Intel pro Speicherkanal auch ein Optane DC Persistent Memory Modul eingesetzt werden, was den Gesamtspeicherausbau auf 6 TB pro Sockel anhebt.
SoC-Design und Fertigung
Gefertigt werden die Ice-Lake-SP-Prozessoren in 10 nm, allerdings in einer verbesserten Variante, wenngleich auch nicht in 10nm SuperFin wie die aktuellen Tiger-Lake-Prozessoren bei den Notebooks. Intel versucht sich hier vermeintlich ein letztes Mal an der problembehafteten Fertigung, die für all diese Verzögerungen geführt hat.

Die größte Chipvariante von Ice Lake-SP bietet bis zu 40 Kerne. Obiges Bild stellt den Aufbau schematisch dar. In einem Mesh organisiert und entsprechend miteinander verbunden, sind die Blöcke im SoC-Design. In der Mitte befinden sich die Sunny-Cove-Kerne, in den Randbereichen die weiteren Komponenten wie die acht Speicherkanäle, vier 16 PCI-Express-4.0-Lanes, die drei UPI-Links und ein DMI/DMA-Interface. Die integrierte Spannungsversorgung (FIVR) teilt sich einen Dummy-Platz, von denen es noch drei weitere gibt.
Details zur Größe der Chips und der Anzahl an Transistoren macht Intel nicht. Es dürfte jedoch wieder mindestens zwei bis drei verschieden große Chips geben. Denkbar wäre eine Aufteilung in LCC (Low Core Count) mit bis zu 18 Kernen, HCC (High Core Count) mit bis zu 28 Kernen und XCC (Extreme Core Count) mit bis zu 40 Kernen.
Die Ice-Lake-SP-Prozessoren verwenden den Sockel LGA4189-4/5 SMT Socket mit eben 4.189 Pins und Abmessungen von 77,5 x 56,5 mm. Verwendeten Skylake-SP und Cascade Lake-SP noch den gleichen Sockel, wechselt Intel nun auf einen neuen – was auch aufgrund der höheren Anzahl an Speicherkanälen und wegen der PCI-Express-4.0-Lanes zwingend notwendig wurde.
Als Chipsatz setzt Intel den C620A ein. Dieser wird über vier DMI-3.0-Links an den Prozessor angebunden und bietet 20 weitere PCI-Express-3.0-Lanes, 10x USB 3.0, 14x USB 2.0 und 14x SATA III.
Bis zu 40 Kerne, aber der Takt steigt nicht
Gewohnt umfangreich stellt Intel eine breite Produktpalette auf. Unterschieden wird zwischen Modellen, die für den 1S- und 2S-Betrieb ausgelegt sind, und solchen für 4S- und 8S-Systeme. Dann gibt es wiederum Modelle, die pro Kern einen besonders hohen Takt erreichen sollen, oder deren SGX Enclave eine besonders hohe Kapazität aufweist. Als Spezialmodelle sind solche zu bezeichnen, die wassergekühlt werden müssen, die auf Cloud-Instanzen ausgelegt, oder die für Netzwerk- oder Media-Anwendungen hin ausgelegt sind.
Ein paar Hinweise zur Namensgebung: Als x3xx bezeichnet werden alle Xeon-Prozessoren auf Basis von Ice Lake-SP. Die Zahlen davor und dahinter unterteilen die gesamte Produktpalette in die Xeon-Platinum- und Xeon-Gold-Serie.
Der Zusatz H und HL beschreibt die Modelle, die in 4S- und 8S-Konfiguration betrieben werden können. Hier gibt es außerdem Unterschiede in der maximalen Speicherkapazität. Die Y-Modelle unterstützen die Speed Select Technology mit den Performance Profilen 2.0 (SST-PP). Die Speed Select Technology generell, aber auch SST Base Frequency (SST-BF), SST Core Power (SST-CP) und SST Turbo Frequency (SST-TF) werden auch von Modellen ohne Y-Zusatz unterstützt - hier muss man genau bei den Modellen in den Details nachsehen. Mit P und V werden Modelle benannt, die für Cloud-Hyperscaler interessant sein sollen. Mit dem M-Zusatz versehen sind die Modelle für Multimedia-Anwendungen – analog zu N für die Netzwerk-Modelle. Wie auch bei den Desktop-Prozessoren beschreibt der T-Zusatz solche Xeon-Prozessoren mit geringerer TDP und die bei höheren Temperaturen betrieben werden können. Es gibt auch noch weitere Namenszusätze und Intels Produktportfolio wird durchaus sehr komplex.
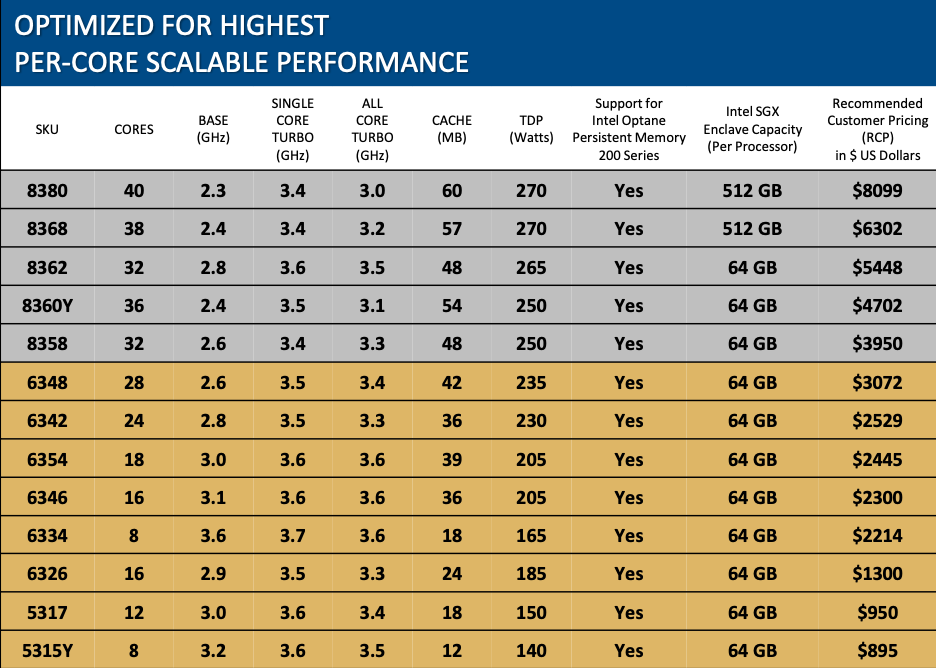
Als "Brot und Butter"-Geschäft dürfen die oben aufgeführten Modelle genannt werden. Hier findet man den Xeon Platinum 8380 mit 40 Kernen, der einen Basis-Takt von 2,3 GHz, einen Single-Core-Turbo von 3,4 GHz und einen All-Core-Turbo von 3,0 GHz vorzuweisen hat. Der Cache hat eine Größe von 60 MB – ist also noch immer nur rund ein Viertel so groß wie bei AMDs EPYC-Prozessoren in der Maximalausstattung. Die TDP liegt bei 270 W und die SGX Enclave kann bis zu 512 GB groß sein. der Optane Persistent Memory wird von allen Modellen unterstütz. Die Xeon-Platinum-Modelle decken die Produktpalette von 32 bis 40 Kernen ab. Xeon Gold startet bei acht und geht bis 28 Kerne. Die Basis- und Boost-Taktraten variieren entsprechend der vorhandenen Kerne und der vorgesehenen TDP. 4 GHz werden aber von keinem der hier aufgeführten Prozessoren erreicht.
Eine TDP von 270 W für den Xeon Platinum 8380 zeigt einen signifikanten Anstieg im Vergleich zum Xeon Platinum 8280 mit 205 W. 40 % mehr Kerne fangen den Mehrverbrauch von 30 % aber auch wieder auf. Cascade Lake-AP bestehend aus zwei Chips gibt es nicht mehr, da Intel nun 40 Kerne im monolithischen Design erreicht.
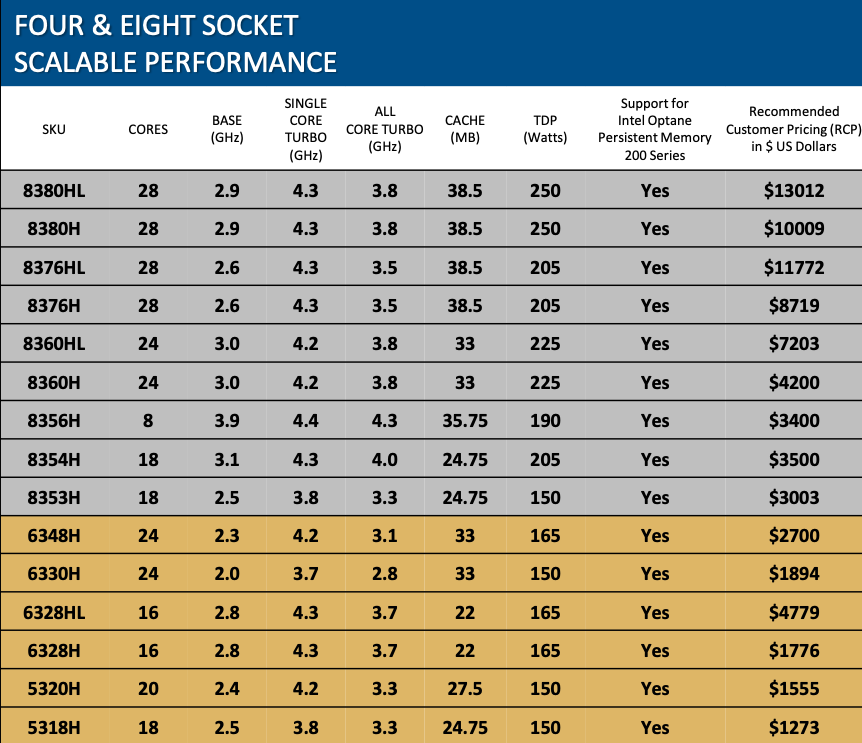
H- und HL-Modelle sind für 4S- und 8S-Systeme vorgesehen und basieren noch auf Cooper Lake. Hier werden maximal 28 Kerne angeboten. Beim Speicher und der Unterstützung von Optane Persistent Memory muss man allerdings wieder genauer hinschauen. Der Single-Core-Turbo erreicht bis zu 4,4 GHz. Hier zeigen sich die höheren Taktraten der 14-nm-Generation.
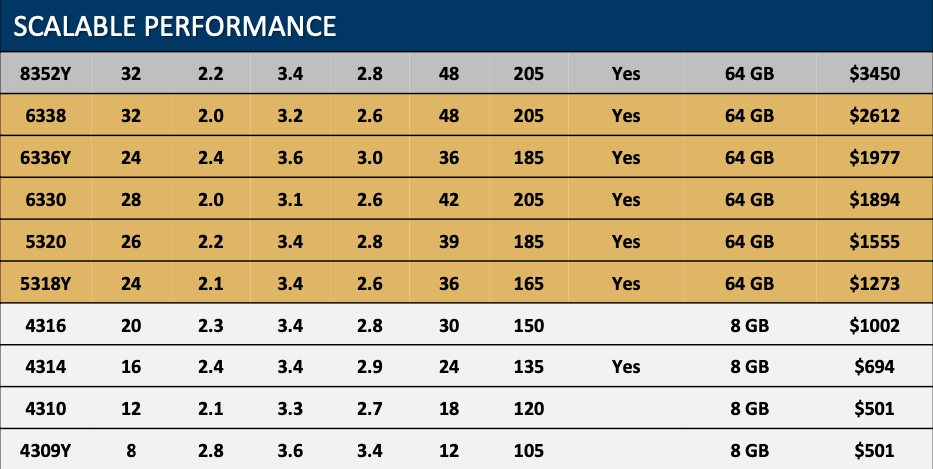
Weniger Fokus auf beispielsweise die SGX Enclave legt Intel bei den Scalable-Modellen, die Platinum-, Gold- und Bronze-Varianten beinhalten. Bis zu 32 Kerne bietet Intel hier, die Taktraten sind als moderat zu bezeichnen, ebenso wie die TDP-Klassifizierung.

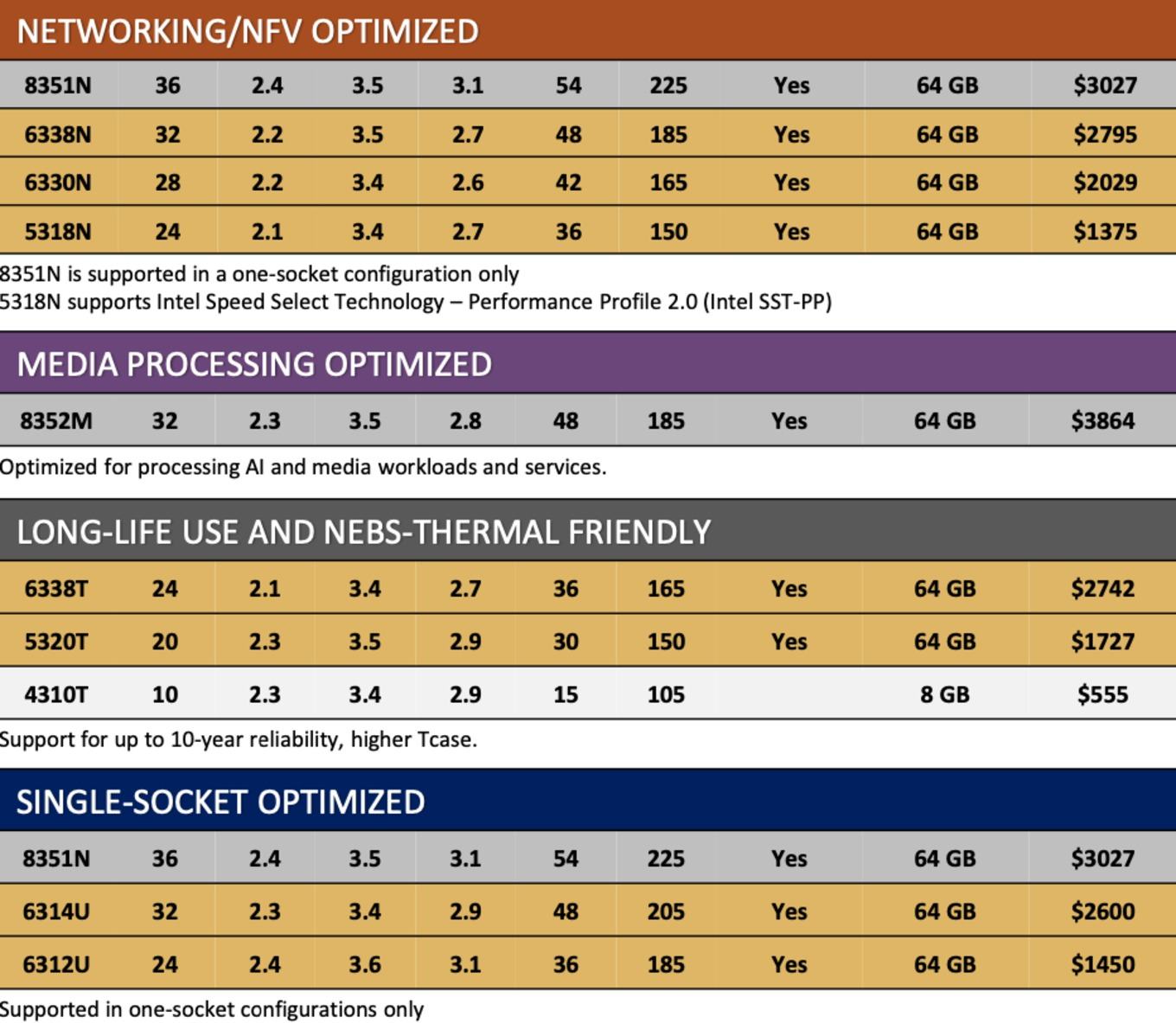
Obige Tabellen zeigen die Sondermodelle, die beispielsweise für höhere Temperaturen ausgelegt, oder für Netzwerk- und Multimedia-Anwendungen vorgesehen sind. Die Taktraten kann man ebenfalls als moderat bezeichnen, das Leistungsplus der 3. Xeon-Generation wird daher ausschließlich über die Anzahl der Kerne und das IPC-Plus der Sunny-Cove-Architektur erreicht.
Sicherheit durch SGX und TME
Mit den Xeon-Prozessoren auf Basis von Ice Lake werden einige Neuerungen, bzw. Verbesserungen Einzug halten. Darunter für Intels SGX, eine Speicherverschlüsselung, Abhärtung der Firmware und eine neue hardwarebeschleunigte Kryptographie.
Basis all dessen soll eine verbesserte Sicherheit im Bereich der Hardware, des BIOS und der Firmware sowie des Betriebssystems, bzw. des Hypervisors sein. Ist eine dieser Komponenten kompromittiert, nützt selbst die Absicherung des darüberliegenden Software-Stacks wenig. Das Thema Sicherheit rückt für Intel in den Fokus, da man in der Vergangenheit viel an Vertrauen verloren hat. Dieses gilt es nun zurückzugewinnen.
Als einer der wichtigsten Schritte für die nächste Xeon-Generation wird Intels SGX (Software Guard Extensions) um die Trusted Execution Enviroment (TEE) ergänzt und erstmals überhaupt kommt SGX in den Xeon-Prozessoren zum Einsatz. Diese Funktion war bereits mit den Xeon-E-Prozessoren verfügbar, findet nun jedoch ihren Weg zu den Scalable-Prozessoren. Software, die TEE verwendet, kann das Betriebssystem und den Hypervisor umgehen, um beispielsweise auf den abgesicherten Speicher zuzugreifen. Code und Daten wird also den gefährdeten Schichten im Software-Stack gar nicht mehr offenbart, was Angriffsvektoren verhindern soll.

Pro Enclave können 1 TB an Daten und Code abgesichert werden. Ein einzelner Xeon-Prozessor kann allerdings nur eine Enclave mit bis zu 512 GB absichern und selbst diese Größe ist nicht mit allen Modellen möglich. Hier muss man genau auf die jeweilige Modellvariante achten. Zwei Ice-Lake-Xeons können in einem 2S-System aber eine Enclave mit 1 TB bilden.
Mit Ice Lake-SP neu ist die Unterstützung für TME (Total Memory Encryption) oder MKTME (Multi-Key Total Memory Encryption). Die mittels TME abgesicherten Daten im Speicher können nur durch einen bestimmten Schlüssel abgerufen werden, der einmalig mit Systemstart erstellt wird. Der Overhead durch die Verschlüsselung soll gerade einmal 3 % betragen, hängt aber sicherlich von der jeweiligen Anwendung ab. AMDs SME (Secure Memory Encryption) und SEV (Secure Encrypted Virtualization) sind bereits auf dem Stand, den Intel mit TME nun erreicht haben will. Im Falle von SME kann ein beliebiger Teil des Arbeitsspeichers verschlüsselt werden. Die TSME (Transparent Secure Memory Encryption) ermöglicht ein Verschlüsseln des kompletten Arbeitsspeichers mit Systemboot. Dies setzt dann keine Vorbereitung der Software auf eine Verschlüsselung in die Form voraus, wie dies bei SME der Fall ist.
Ein weiterer Baustein stellt die Platform Firmware Resilience (PFR) dar. Dazu wird ein Intel-FPGA verwendet, das eine Root of Trust implementiert und kritische Komponenten wie die Firmware validiert – im Falle einer Modifikation soll diese erkannt und korrigiert werden. Überwacht werden können das BIOS, die Plattform-Firmware, der Prozessor und eventuell vorhandene Wiederherstellungs-Images. Intels PFR, bzw. der FPGA überwacht zudem die wichtigen System-Bus-Systeme und erkennt, bzw. filtert Traffic, der auf Schadcode hinweisen könnte. Als eine Art Firewall wird dieser Traffic dann im Zweifel blockiert, um die dazugehörige Attacke zu blockieren.
Optane Persistent Memory, Optane-SSDs und schnelles Netzwerk
Natürlich stehen bei der 3. Generation der Xeon-Prozessoren die bis zu 40 Kerne auf Basis der Sunny-Cove-Architektur im Fokus. Hinzu kommt die Plattform mit 8x DDR4-3200, 64x PCIe 4.0 und 3x UPI. Intel wird jedoch nicht müde, auch die weiteren Vorteile hervorzuheben.

Intel stellte Mitte des vergangenen Jahres die Optane Persistent Memory 200 Series alias Barlow Pass vor. Wichtigstes Merkmal ist die höhere Speicherbandbreite (+25 %) im Vergleich zur ersten Generation, denn die Optane-DIMMs können mit gleichem Takt wie der Arbeitsspeicher (DDR4-3200) angesprochen werden.
Maximal die Hälfte der DIMM-Steckplätze eines Xeon-Prozessors kann mit Optane DC Persistent Memory bestückt werden (pro Kanal jeweils ein DRAM und ein Persistent Memory Modul). Der Speicher ist in DIMMs mit einer Kapazität von 128, 256 und 512 GB verfügbar. Der maximale Speicherausbau beläuft sich somit auf 8x 256 GB DDR4 + 8x 512 GB Optane DC Persistent Memory - also insgesamt 6 TB pro Sockel.
Wie der Optane DC Persistent Memory in den Anwendungen verwendet wird, ist wie bislang von der konkreten Umsetzung abhängig. Im App Direct Mode erfolgt eine dedizierte Auslegung der Zugriffe auf den Speicher. Intel hat dazu ein Standard Programming Model entwickelt, über das alle Applikationen im App Direct Mode mit dem Optane DC Persistent Memory sprechen.
Im zweiten Modus, dem Storage over App Direkt, wird der Optane DC Persistent Memory wie eine SSD oder HDD behandelt. Es gibt Blockgrößen und Dateisysteme, mit denen die Daten auf den Speicher geschrieben und davon gelesen werden können. Zudem gibt es einen Mixed Mode, in dem bestimmte Speicherkanäle jeweils unterschiedlich angesprochen werden können.

Als weitere Speicherebene sieht Intel die Optane-SSDs vor. Zu den Neuheiten des vergangenen Jahres gehört die Optane SSD P5800X mit der zweiten Generation des Optane-Speichers, der hier in Form einer PCI-Express-4.0-SSD umgesetzt wird. Die Optane SSD P5800X soll um den Faktor drei schneller sein als ihr Vorgänger, die Optane SSD P4800X. Der verbesserte Optane-Speicher ist einer der Punkte, der zur höheren Leistung beiträgt. Ein weiterer ist die Tatsache, dass die Optane SSD P5800X per PCIe 4.0 mit vier Lanes angebunden ist und damit die Voraussetzungen für einen hohen Datendurchsatz hat. Intel spricht von 7,2, bzw. 6,2 GB/s für das Lesen und Schreiben von Daten. Für 4K-Daten liegen die IOPS bei 1,5 Millionen. Für 512Byte-Zugriffe sind es sogar 4,6 Millionen IOPS.
Ein Faktor, der bei den Optane-SSDs eine besondere Rolle spielt, ist die Umstand, dass sie bei hohen Datenraten noch niedrige Latenzen im Bereich von 10 bis 100 ns vorzuweisen haben. Während die Latenzen bei klassischen SSDs von 100 ns mit zunehmender Bandbreite immer weiter ansteigen, bleiben sie bei der Optane SSD P5800X selbst bei 8 GB/s noch im niedrigen Bereich.
Die DWPD (Drive Writes Per Day) gibt Intel mit 100 an. Die Kapazität der SSD beträgt je nach Modell 400 GB, 800 GB, 1,6 TB oder 3,2 TB.


Weitere Bestandteile des Plattform-Ökosystems sind die Netzwerk-Adapter, die dank PCI-Express 4.0 deutlich schneller angebunden werden können und die 2x 100 GBit/s erreichen. Die Protokolle wie RDMA iWARP und RoCEv2 sollen sicherstellen, dass die maximale Datenübertragungsraten, geringe Latenzen und ein gewisses Level an QoS sichergestellt werden.
Letzter wichtiger Baustein sind die FPGAs der Agilex-Serie. Diese wurden bereits vor einigen Monaten offiziell vorgestellt, sollen nun aber in die Massenproduktion gehen, bzw. sind erst zusammen mit den ICX-Prozessoren besser eingebunden in die Produktpalette.
Intels eigene Benchmarks
Natürlich liefert Intel zum heutigen Start eigene Benchmarks, die die Vorteile unter Beweis stellen sollen. Ohne spezielle Softwareoptimierungen und eine Auslegung auf bestimmte Befehlssätze soll das Leistungsplus bei 50 bis 74 % liegen. Mit diesen Optimierungen im Bereich der VNNI-Beschleunigung soll es sich um den Faktor 10 handeln.

Dabei zieht Intel den Vergleich zum Vorgänger Cascade Lake. Gegenüber Skylake-SP oder gar Haswell ist das Leistungsplus natürlich noch größer. Hier spielen einzig die Architektur, eventuell das Taktplus und die Anzahl der Kerne eine Rolle, genau wie die VNNI-Beschleunigung und spezielle AVX512-Optimierungen.

Intel vergleicht sich natürlich auch mit AMD. Hier zieht man bereits die EPYC-Prozessoren der dritten Generation heran – also die aktuellen Chips mit Zen-3-Kernen. Allerdings zieht Intel nur Vergleiche in Anwendungen, die per AVX512 beschleunigt werden können. Trotz des Nachteils von weniger Kernen (2x 40 vs. 2x 64) kann Intel so ein Leistungsplus für sich verbuchen. Noch eklatanter sieht dies im Bereich der AI-Berechnungen aus, wo dann die VNNI-Beschleunigung zu Tragen kommt. Erstellt AMD entsprechende Benchmarks, wird man natürlich ebenfalls solche Anwendungen wählen, die der eigenen Hardware gut zu Gesicht stehen.
Verfügbarkeit ist Intels Trumpf
Die ungebrochene Marktmacht im Datacenter und auch die enge Bindung der Hardware an weitere Komponenten und vor allem die Software, aber womöglich auch die Verfügbarkeit der dritten Xeon-Generation könnten Intels Trumpf sein. Bei AMD wird man hinsichtlich der Verfügbarkeit ähnliche Probleme haben, wie bei den Desktop-Modellen - schließlich teilen sich alle Chips die gleiche Fertigung bei TSMC (und in Form der CCD sind die Compute-Chips sogar komplett identisch und werden in gleich zwei Produktkategorien verwendet).
Mit 40 gegen 64 Kerne pro Sockel und 64 gegenüber 128 PCI-Express-Lanes hat AMD weiterhin den Vorteil der höheren Kerndichte und besseren Anbindung von weiteren Komponenten. Hinsichtlich der Speicherausstattung hat Intel mit einem Achtkanal-Speicherinterface wieder aufgeschlossen. Auch bei der Kapazität und der Speichergeschwindigkeit ist Intel mindestens wieder auf Augenhöhe.
Ob ein Server nun mit einem EPYC- oder Xeon-Prozessor ausgestattet ist hängt aber wie so oft auch von der jeweiligen Anwendung ab. Das Datacenter-Geschäft ist nicht nur rein von Benchmarks abhängig, sondern hier gibt es auch vielerlei weitere Abhängigkeiten.
Etwas überraschend und auch ein eindeutiges Zeichen das Intel die Zeichen der Zeit erkannt ist ist, dass man die Preise angepasst hat. Der Xeon Platinum 8380 kostet "nur" noch 8.099 US-Dollar – 20 % weniger als der Vorgänger. Noch eindeutiger zeigt sich das Bild in der Mittelklasse, wo die Prozessoren im Vergleich um bis zu 60 % günstiger als die Vorgänger sind. Hier ist die EPYC-Konkurrenz wohl am deutlichsten spürbar. Allerdings muss man auch wissen, dass die aufgeführten Listenpreise meist wenig mit dem zu tun haben, was vor allem Großkunden für die Prozessoren bezahlen. Hier gibt es sowohl seitens AMD, aber auch von Intel signifikante Rabatte.
Bei AnandTech gibt es bereits einen ersten Test zu Ice Lake-SP, so dass neben den von Intel zur Verfügung gestellten Daten auch noch weitere zur Verfügung stehen.



 mit Ice Lake-SP")
