
Werbung
Auf der CES 2025 stellte AMD mit dem Ryzen AI Max+ 395 den weltweit ersten Windows-AI-PC-Prozessor vor, der in der Lage ist, Llama 70B lokal auszuführen. Diese Funktion wird durch die Integration von llama.cpp und LM Studio ermöglicht und stellte einen wichtigen Schritt für die Bereitstellung großer Sprachmodelle auf lokalen Windows-Systemen dar. Nun kündigte AMD eine Erweiterung der variablen Grafikspeichernutzung an, die es ermöglicht, Modelle mit bis zu 128 Milliarden Parametern in Vulkan llama.cpp auf Windows auszuführen. Diese Verbesserung wird mit den kommenden Adrenalin Edition 25.8.1 WHQL-Treibern eingeführt und erlaubt es, speicherintensive KI-Workloads vollständig auszunutzen, insbesondere auf Maschinen wie dem Ryzen AI Max+ 395 mit 128 GB, der über 96 GB variablen Grafikspeicher verfügt.
Mit diesem Upgrade wird der Ryzen AI Max+ 395 so zum weltweit ersten Windows-AI-PC-Prozessor, der in der Lage ist, Metas Llama 4 Scout 109B mit voller Vision- und MCP-Unterstützung auszuführen. Dieses Modell verwendet eine Mixture-of-Experts-Architektur, bei der nur 17 Milliarden Parameter gleichzeitig aktiv sind, während alle 109 Milliarden Parameter im Speicher gehalten werden müssen. Dies ermöglicht eine praxisnahe Ausgabe von bis zu 15 Tokens pro Sekunde und soll das Modell zu einem leistungsfähigen Begleiter für mobile KI-Anwendungen machen.
Nutzer sollen so flexibel auf kleinere Modelle wechseln können, wenn eine höhere Geschwindigkeit erforderlich ist, wobei die Leistung jeweils von der Anzahl der aktiven Parameter abhängt.


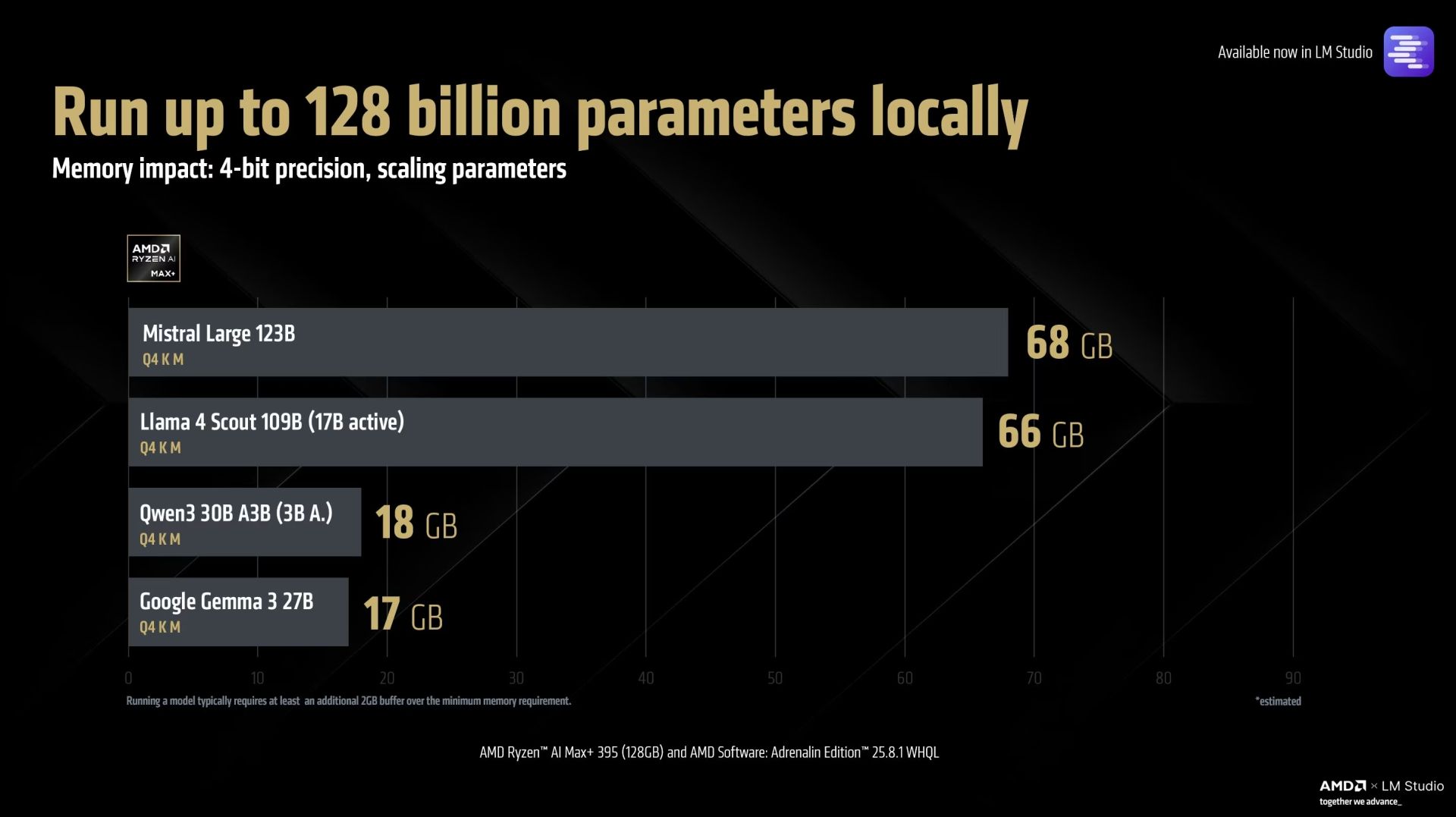
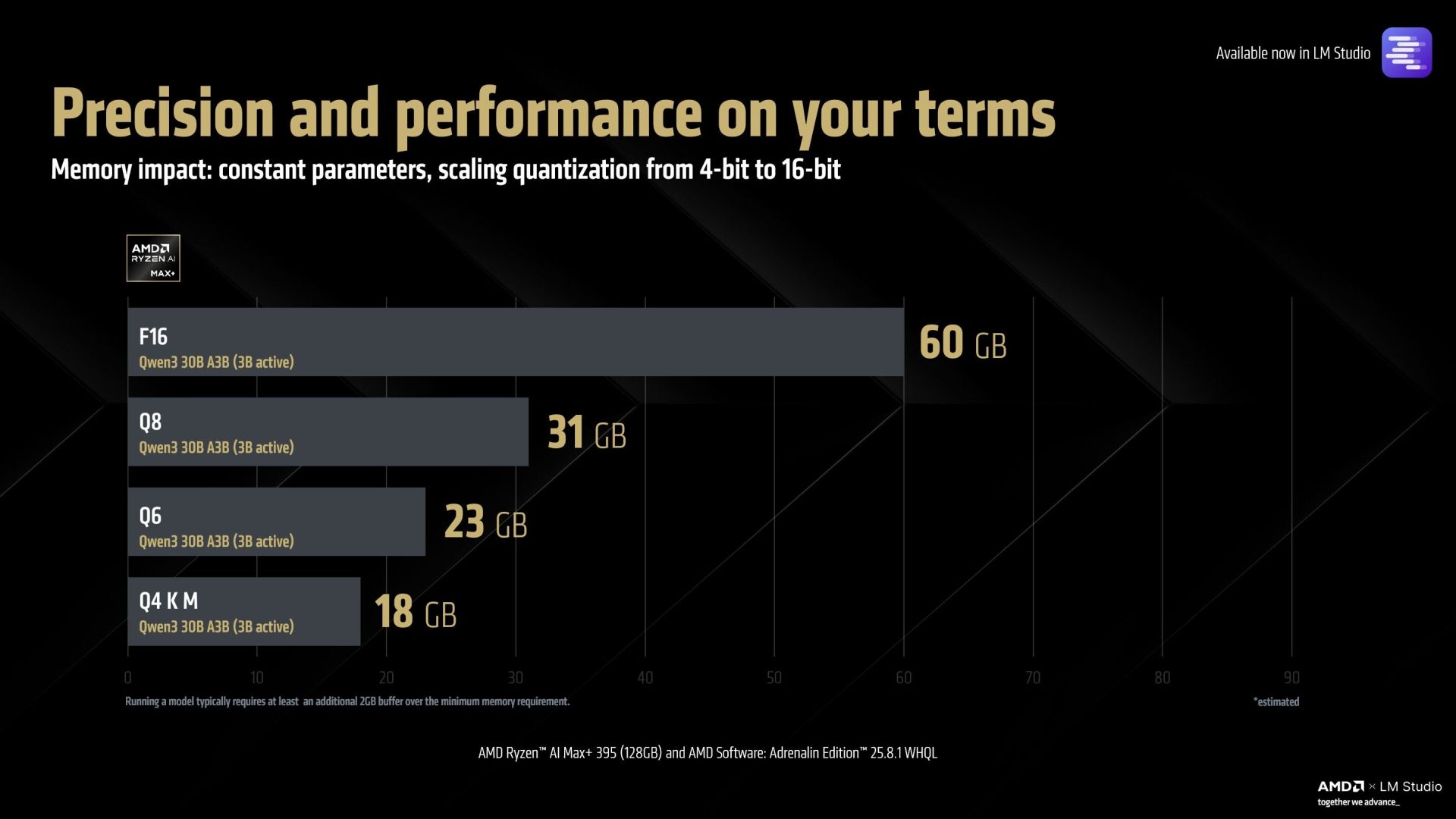


Der Prozessor unterstützt Modelle von kleineren 1B-Varianten bis hin zu großen Sprachmodellen wie Mistral Large, die über llama.cpp mit unterschiedlichen Quantisierungseinstellungen betrieben werden können. Aufgrund der großen Speicherkapazität ist sogar der Betrieb von 16-Bit-Modellen möglich. Höhere Modellparameter können die Ausgabegenauigkeit verbessern, während angepasste Quantisierung zusätzliche Optimierungsspielräume eröffnet.
Ein weiterer entscheidender Faktor für die Leistungsfähigkeit moderner KI-Anwendungen ist die Größe des Kontextfensters. Während die Standardeinstellung in LM Studio bei 4096 Tokens liegt, ermöglicht der Ryzen AI Max+ 395 mit den neuen Treibern den Betrieb von Llama 4 Scout bei einer Kontextlänge von 256.000 Tokens. Diese enorme Kapazität eröffnet neue Möglichkeiten für agentische Workflows, die große Mengen an Kontextinformationen benötigen.
Demonstrationen zeigen, dass komplexe Aufgaben wie das Abrufen und Zusammenfassen umfangreicher SEC-Dokumente oder das Analysieren wissenschaftlicher Arbeiten aus der ARXIV-Datenbank problemlos bewältigt werden können. Diese Anwendungsfälle erfordern oft weit über 20.000 Tokens im Kontext – weit mehr als die bisher üblichen Limits. Für Power-User, die komplexe Multi-Tool-Workflows ausführen, sind große Kontextfenster unverzichtbar, während Gelegenheitsnutzer oft mit geringeren Einstellungen auskommen.
