P
pillenkoenig
Guest
Wart halt 3 Jahre, dann bekommst du 30-40% mehr. Jedes Jahr aufrüsten ist halt auch dämlich?
Follow along with the video below to see how to install our site as a web app on your home screen.

Anmerkung: this_feature_currently_requires_accessing_site_using_safari
1030 ist 750 Ti Leistung. Die 1050 reicht auch nur noch sehr knapp für 1080p (mit reduzierten Settings). Da wird man bei jeder iGP kaum drum kommen.Wobei zumindest die 1030 auch nur für Windows Desktop und Multimedia taugt, wer irgendwelche Ansprüche an Gamingperformance hat, der sollte von der 1030 die Finger lassen oder damit zufrieden sein was er bekommt und sich darüber freuen, dass sie billig ist. Genau dies gilt auch für die iGPUs.
Selbst wenn die bei Zen 4 nicht kommen, so sind Refreshs / neue Gens möglich. Damals haben manche auch nicht geglaubt dass Zen auf AM4 mal mit 16 Kernen kommt.Ja aber doch genau diesen Wert haben wir ja noch nicht, wir wissen nur was der Sockel theoretisch kann. Aber nicht was die CPU die präsentiert wurde gebraucht hat.
Wir wissen auch, das der neue Sockel auch für große CPUs angedacht wurde, also auch 24 Kerne stehen im Raum. Das diese die volle Power brauchen werden ist definitiv logisch nachvollziehbar, bei den anderen muss das nicht sein.
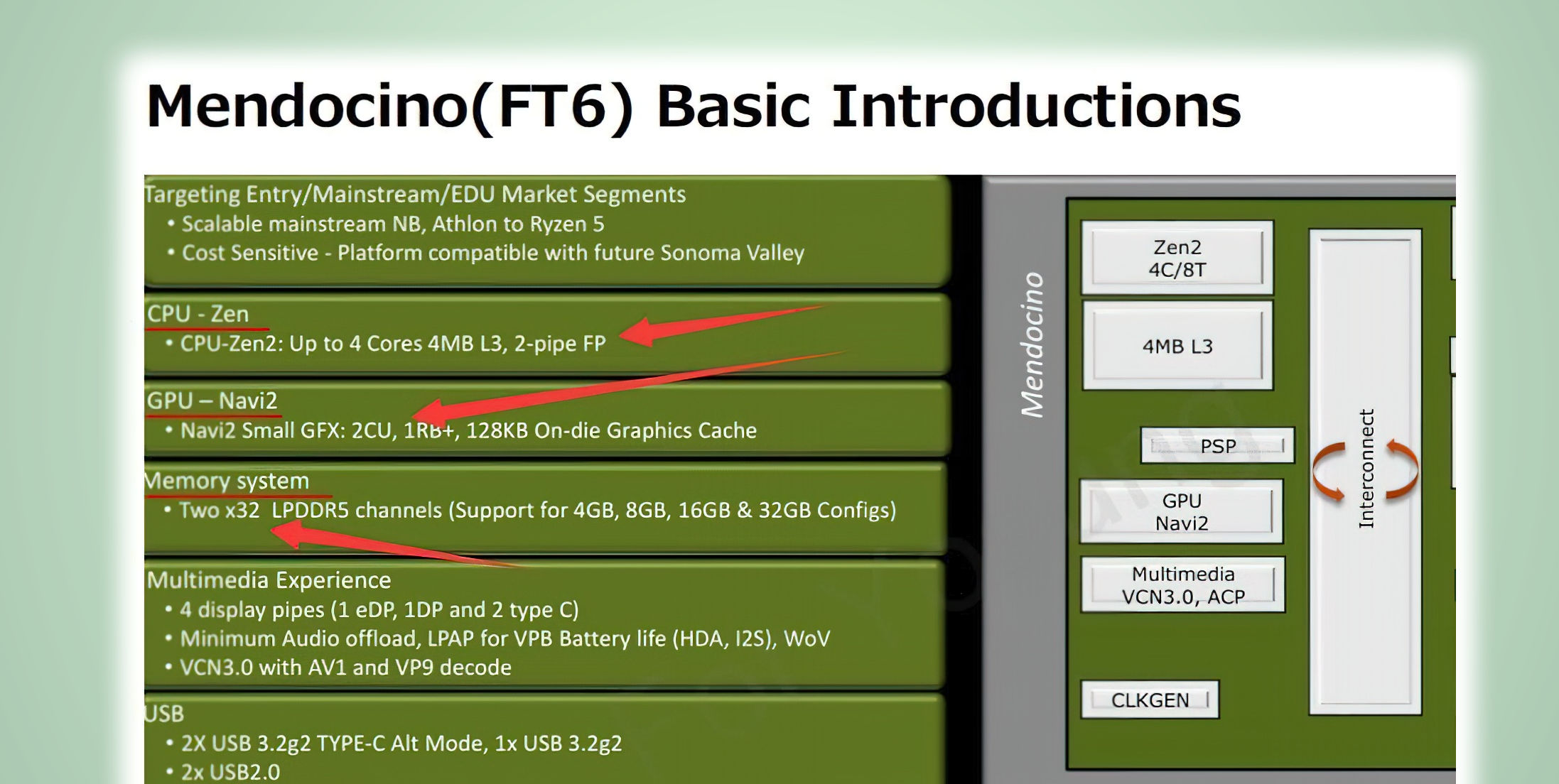
 videocardz.com
videocardz.com
AMD Ryzen 7000, Raphael-GPU soll nur über 128 RDNA2-Shader verfügen:
Leaked slide confirms AMD Mendocino RDNA2 graphics specifications with two Compute Units - VideoCardz.com
AMD Mendocino confirmed with 2 Compute Units A block diagram and information on AMD low-power Mendocino APU confirms its specifications. The slide was first posted on a (closed?) WeChat group and then reposted by Chiphell. From there, Twitter user Olrak29_ managed to find the original slide...
Damit wäre die Raphael-GPU deutlich langsamer als die aktuelle APU-Generation, was schon eine Enttäuschung wäre. /:
Vorsicht, es gibt zwei Varianten der 1030, eine mit GDDR5 RAM und eine mit DDR4 RAM, die deutlich langsamer ist und auch sonst liegt die 750TI in vielen Vergleichen vorne:1030 ist 750 Ti Leistung.
Die GDDR5 Version hat zwar 48GB/s Speicherbandbreite, bleibt damit aber immer noch deutlich unter den 69,6GB/s der 750Ti, so wie sie in allen anderen Punkten eben auch hinter der 750Ti liegt.
Eben, die reichen allenfalls für die meisten Games nur für Gaming mit Minimalansprüchen bzgl. der Settings und fps. Ob man sich das wirklich antun will und es noch Spaß macht, muss natürlich jeder selbst wissen, denn geht gar nicht ist ja nicht nur eine Frage ob ein Spiel mit der Konfiguration überhaupt startet, sondern ob es eben auch so spielbar ist, dass es Spaß macht.Die 1050 reicht auch nur noch sehr knapp für 1080p (mit reduzierten Settings). Da wird man bei jeder iGP kaum drum kommen.
gibt es eigentlich schon einen Termin, wann der Zen 4 (16 Kerner) rauskommt,
Also nach meiner Info, gibt es noch keinen finalen Termin. Nur Quartal 4Hallo zusammen,
gibt es eigentlich schon einen Termin, wann der Zen 4 (16 Kerner) rauskommt, habe da mal Herbst gelesen, aber nichts näheres. Leider werden die neuen Grakas wohl erst Ende des Jahres auf den Markt kommen ?
Danke !
Viele Grüße,
Schnitzel
Die Speicherbandbreite sagt nichts über die Leistung aus. Siehe hier:Vorsicht, es gibt zwei Varianten der 1030, eine mit GDDR5 RAM und eine mit DDR4 RAM, die deutlich langsamer ist und auch sonst liegt die 750TI in vielen Vergleichen vorne:
Die GDDR5 Version hat zwar 48GB/s Speicherbandbreite, bleibt damit aber immer noch deutlich unter den 69,6GB/s der 750Ti, so wie sie in allen anderen Punkten eben auch hinter der 750Ti liegt.
Mit der Meinung stehst du aber reichlich alleine da und der Vergleich der Performance der beiden 1030 Varianten, den ich ja schon im letzter Post verlinkt hatte, beweist das Gegenteil. Bei den restlichen Daten liegt die 1030 auch hinten.Die Speicherbandbreite sagt nichts über die Leistung aus
Ohne eine Beschreibung des Testsystems und der jeweiligen Einstellungen ist so ein Video wertlos. Teils war die CPU bei 100% Auslastung und beim kurzen Reinschauen in die Scenen lag die 750Ti immer vorne, teils mit mehr als 10% mehr fps. Aber es ist bei den beiden sowieso sinnlos die bessere bestimmen zu wollen, dies wäre wie die Frage zu beantworten oder Hunde- oder Katzenscheiße besser schmeckt.Siehe hier:
Meine Vega reisst ein halbes TB/s. Muss ja eine perverse Granate sein, Benchmarks ueberfluessig!Mit der Meinung stehst du aber reichlich alleine da und der Vergleich der Performance der beiden 1030 Varianten, den ich ja schon im letzter Post verlinkt hatte, beweist das Gegenteil. Bei den restlichen Daten liegt die 1030 auch hinten.
Die 4 Lanes mehr machen das Brot ja auch soviel besserWas mir schon mal richtig gut gefällt sind die 24 PCIE 5.0 Lanes

Beim Intel sind es aktuell nur 1*16 PCIE 5.0 soweit ich das richtig verstanden habe und wen man eine m.2 drauf packt mit 5.0 wird das von der Graka abgezwackt die dann nur noch 8 Fach läuft!Die 4 Lanes mehr machen das Brot ja auch soviel besser

Die Alder-Lake-Prozessoren bieten insgesamt 16 PCI-Express-5.0-Lanes. Diese können in 1x 16 oder 2x 8 Lanes aufgeteilt werden. Eine weitere Aufteilung in 1x 8 und 2x 4 Lanes ist nicht möglich. Für NVMe-SSDs sieht Intel in der Alder-Lake-Plattform vier Lanes auf Basis von PCI-Express 4.0 vor, auch wenn einige Mainboardhersteller je nach Modell die PCIe-5.0-Lanes auch in M.2-Steckplätze überführen, was dann aber wiederum zu einer Aufteilung der 16 Lanes in zweimal acht führt.

Aber kein PCie 5.0 ohne die GPU zu beschneiden !Mag sein, aber du vergisst da den Chipsatz der ebenfalls noch was zur Verfügung stellt. Und mal ehrlich, 2x NVMe-SSDs reichen für jeden normalo aus.
Bei mir ist aktuell einer über die CPU angebunden zwei über den Chipsatz sind noch verfügbar.
So schön das ist bei AMD, werden die meistens das gar nicht ausnutzen.
Sagen wir mal lieber das Alder Lake dahingehend bescheiden ist, bei seinem Nachfolger Raptor Lake könnte Intel sicher recht einfach die weiteren 4 PCIe Lanes der CPU, die normalerweise für den M.2 Slot sind, auch auf PCIe 5.0 bringen. Raptor Lake dürfte der eigentliche Konkurrent der RYZEN 7000 sein, da beide etwa zur gleichen Zeit auf den Markt kommen dürften.Die Alderlake Plattform ist dahingehend bescheiden!
Naja das sind 8x PCIE4.0 oder 16x 3.0 in Geschwindigkeit. Das ist schon nicht ohne. Reicht für Datenträger satt.Die 4 Lanes mehr machen das Brot ja auch soviel besser
Eben, derzeit gibt es noch nicht einmal eine PCIe 5.0 Consumer SSDs und die werden im M.2 Formfaktor das Problem mit Leistungsaufnahme (es sind nur etwas mehr als 8W erlaubt!) und Kühlung nur noch stärker haben als PCIe 4.0 SSDs. Dazu kommt, dass sie noch mehr lange und parallele Zugriffe brauchen werden um überhaupt auf höhere Transferraten zu kommen und die sind im Alltag bei Heimanwendern extrem selten.Natürlich ist die Frage, wer kann das brauchen?
Aber da werden die jeweils 8 Lanes die von der CPU bzw. des Chipsatz zur Anbindung eben des Chipsatzes genutzt werden, eben mitgezählt und ohne Chipsatz geht es da auch nicht. Auf der Folie stand damals "72 Available PCIe 4.0 Lanes":
Einerseits deutet mindestens ein M.2 Slot mit PCIe 5.0 selbst beim B650, der wohl selbst kein PCIe 5.0 bietet und wo für die Mainboards offenbar nicht einmal PCIe 5.0 für die Graka verlangt (oder gar möglich?) ist schon darauf hin, dass auch 2 möglich sein könnten und diese müssten dann mit Lanes von der CPU versorgt werden, es könnten aber natürlich auch zwei Slots mit je nur 2 Lanes sein, ggf. nur in dem Fall das beide bestückt sind. Während dies aber eher auf mehr PCIe Lanes von der CPU als bei AM4 hindeutet (auch wenn es das nicht beweist), so ist genau die gleiche Anforderung beim X670E doch eher ein Hinweis auf das Gegenteil, denn wieso sollte ein X670E Board nicht beide M.2 Slots mit PCIe 5.0 Anbinden müssen, wenn es genug PCie 5.0 Lanes von der CPU gäbe um zwei M.2 Slots mit je 4 PCIe Lanes anzubinden und wieso ist von "x8/x8/x4" und nicht "x8/x8/x4/x4" die Rede, wenn es doch "24 PCIe 5.0 lanes for storage nad graphics" geben soll?
Du bringst Dinge durcheinander.Damit wäre die Raphael-GPU deutlich langsamer als die aktuelle APU-Generation, was schon eine Enttäuschung wäre. /:
Laut Handbuch kann das Taichi doch aber die SATA Ports + 3x m.2 oder 2x m.2 + den 4x angebundenen unteren PCIe Slot bei vollem 16x Speed des Haupt PCIe Slots nutzen??@Holt
Mein Taichi X570 läuft gerade so mit den 24 PCIE 4.0 Lanes!
16*Lanes PCIE 4.0 für die GPU
4*Lanes PCIE 4.0 M.2 direkt an den Lanes der CPU
4*Lanes PCIE 4.0 über die CPU welche am Chipsatz gekoppelt sind für M.2 4.0 /3.0 dadurch fallen die SATA Ports dann weg!
Also 2 PCIE 4.0 M.2 Festplatten möglich ohne die PCIE 4.0 16 Fach Lanes für die GPU zu stutzen!
Ehrlich gesagt erschließt sich mir der Sinn davon nicht. Raid 1, also als Mirror ergibt Sinn für die Erhöhung der Datensicherheit. Damit brauchts aber die Bandbreite nicht zwingend bzw. es ist fraglich, warum man Raid 1 mit drei SSDs machen sollte, damit das theoretisch ein Problem sein soll.So wird es nun auch bei X670 sein was halt Mega ist wen man z.b ein RAID machen will ohne Abstriche zu machen !
Erst wen ich jetzt noch ne 3 PCIE 4.0 M.2 reinbauen würde würde ich die GPU auf 8 Fach limitieren!
Tolle und falsche Annahme... AMD hat doch nicht die GPU eingebaut, damit 50% des IO Chiplets nicht leer bleiben...Wie ich schon vermutet hatte, ist der I/O Die kaum kleiner geworden, obwohl er nun in 6nm statt vorher 12nm gefertigt wird und die Verbindungstechnologie ist immer noch die gleiche, also ohne Halbleiterinterposer. Damit braucht AMD einfach die Fläche beim I/O Die um die ganzen Anschlüsse unterbringen zu können und hätte den Platz eben einfach freilassen müssen, auf dem sie die iGPU untergebracht haben. Da haben sie meiner Meinung nach die richtige Wahl zwischen Platz sinnlos verschwenden oder sinnvoll nutzen getroffen.

