
Werbung
Aus Sicht eines Redakteurs war die gestrige Präsentation der GeForce-RTX-3000-Serie etwas schwierig in der Abwicklung. Zwar präsentierte NVIDIA im Stream einige Details, das Gesamtbild ergab sich jedoch erst, wenn man die Produktseite mit hinzuzog und noch weitere Quellen anzapfte. Inzwischen haben wir ein gewisses Bild der neuen Karten, aber es fehlen noch immer einige Details. Eben auf diese Unklarheiten wollen wir nun etwas genauer eingehen, denn immer wieder tauchen im Forum die selben Fragen auf.
Aktuell sieht es so aus, als sei NVIDIA mit seinen Founders Editionen der einzige Hersteller, der den 12-Pin PCIe Molex Micro-Fit 3.0 verwendet. Kein Partner hat ein Custom-Modell mit diesem Stecker vorgestellt. Im Bereich der zusätzlichen Stromversorgung verwirrt NVIDIA zudem durch die Angabe, dass für die GeForce RTX 3090 und GeForce RTX 3080 "2x PCIe 8-polig" und für die GeForce RTX 3070 "1x PCIe 8-polig" notwendig seien. Diese Angaben beziehen sich auf die Kompatibilität mit dem eingesetzten Netzteil. Die Karte wird über den 12-Pin-Anschluss versorgt, der entsprechende Adapter liegt bei.









In der Tabelle folgen die bisher bekannten und bestätigten technischen Details:
| GeForce RTX 3090 | GeForce RTX 3080 | GeForce RTX 3070 | |
| GPU | Ampere | Ampere | Ampere |
| Fertigung | 8 nm | 8 nm | 8 nm |
| Shadereinheiten | 10.496 | 8.704 | 5.888 |
| Basis-Takt | 1.400 MHz | 1.440 MHz | 1.500 MHz |
| Boost-Takt | 1.700 MHz | 1.710 MHz | 1.730 MHz |
| Shaderleistung | 36 TFLOPS | 30 TFLOPS | 20 TFLOPS |
| Tensor-Leistung | 285 TFLOPS | 238 TFLOPS | 163 TFLOPS |
| RT-Leistung | 69 TFLOPS | 58 TFLOPS | 40 TFLOPS |
| Speicherkapazität | 24 GB | 10 GB | 8 GB |
| Speichertyp | GDDR6X | GDDR6X | GDDR6 |
| Speicherinterface | 384 Bit | 320 Bit | 256 Bit |
| TDP | 350 W | 320 W | 220 W |
| Preis | 1.499 Euro | 699 Euro | 499 Euro |
| Verfügbarkeit | 24. September | 17. September | Oktober |
Hier gäbe es noch einige Lücken zu füllen: So spricht NVIDIA bei den Kernen von 10.496 CUDA-Kernen für die GeForce RTX 3090, 8.704 CUDA-Kernen für die GeForce RTX 3080 und von 5.888 CUDA-Kernen für die GeForce RTX 3070. Im Vergleich zur GeForce RTX 2080 Ti mit 4.352 Shadereinheiten klingt dies nach einer deutlichen Steigerung.
Wir kennen den Aufbau der Streaming Multiprocessoren (SM) für die neuen GeForce-RTX-Karten noch nicht. Offenbar hat NVIDIA die Anzahl der FP32-Recheneinheiten verdoppelt. Dies würde bedeuten, dass nicht mehr nur 64 FP32-Recheneinheiten pro SM vorhanden sind, sondern 128. Bei 82 SMs der GeForce RTX 3090 ergeben sich bei 128 FP32-Recheneinheiten pro SM dann die von NVIDIA angegebenen 10.496 CUDA-Kerne. Analog gilt dies natürlich für die GeForce RTX 3080 und GeForce RTX 3070. Ob sich die Anzahl der INT32-Recheneinheiten verdoppelt hat, lässt sich derzeit kaum abschätzen. Ein Verhältnis von 1:2 zwischen INT32- und FP32-Recheneinheiten entspricht aber ziemlich genau dem, was NVIDIA an Anforderungen durch Spiele schon bei der Turing-Architektur propagiert hat.
Bei den RT und Tensor Cores sind ebenfalls noch einige Fragezeichen vorhanden, denn auch hier kennen wir noch nicht die Anzahl der Einheiten pro SM. Mit der GA100-GPU hat NVIDIA die verbesserten Tensor Cores bereits vorgestellt und offenbar kommen diese 1:1 bei den GeForce-Karten zum Einsatz. Da die GA100-GPU auf RT Cores verzichtet, tappen wir weiterhin im Dunkeln.
Wir werden abwarten müssen, bis NVIDIA offiziell über die GeForce-Variante der Ampere-Architektur spricht. Wann es soweit ist, können wir aktuell noch nicht sagen.
NVIDIA verwirrt mit Effizienzangaben
Etwas verwirrend waren die Angaben NVIDIAs, die neuen GeForce-RTX-Karten seien um den Faktor x1,9 effizienter als die Turing-Vorgänger. Das entsprechende Diagramm dazu muss man sich ganz genau anschauen, um zwischen den von NVIDIA veröffentlichten Angaben und der tatsächlichen Effizienzsteigerung unterscheiden zu können.

NVIDIA nimmt eine Framerate von 60 FPS als Basiswert und übernimmt die dazu notwendigen 240 W für eine Turing-Karte. Dies vergleicht man dann mit der notwenigen Leistungsaufnahme für 60 FPS einer Ampere-Karte und landet bei etwa 130 W. 240 zu 130 W ergeben in etwa die um den Faktor x1,9 höhere Effizienz.
Eigentlich müsste NVIDIA allerdings die Leistung bei einer bestimmten Leistungsaufnahme miteinander vergleichen. Nehmen wir also wieder die 240 W für 60 FPS bei Turing, kommen wir bei 60 FPS für Ampere auf etwa 90 FPS. Wir sprechen hier also von einem um 50 % höheren Verhältnis der Leistung pro Watt. Dies ist noch immer sehr viel, entspricht jedoch nicht dem Faktor x1,9 wie ihn NVIDIA verkündete.
Was NVIDIA gemacht hat, ist schlicht und ergreifend ein Vergleich, der Turing außerhalb des idealen Effizienzfensters mit Ampere innerhalb des idealen Effizienzfensters gegeneinander stellt. Bei 240 W wird eine Karte mit Turing-GPU nicht im idealen Spannung/Takt-Verhältnis betrieben, während die Ampere-GPU mit 240 W noch im Bereich der guten Effizienz arbeiten kann.
Ja, die neuen GeForce-RTX-Karten bieten ein deutlich höhere Leistung, NVIDIA benötigt dazu aber auch eine GPU mit 28 Milliarden Transistoren und setzt die GeForce RTX 3090 auf eine TDP von 350 W und selbst die GeForce RTX 3080 genehmigt sich noch 320 W. Dies muss natürlich bei der Effizienz der Karten mit bedacht werden und spielt eine Rolle.
Weitere Details folgen
In den kommenden Tagen wird es sicherlich noch weitere Details geben. Die Presse und damit auch wir werden mit zusätzlichen Informationen versorgt werden, um die entsprechenden Tests vorbereiten zu können.
Am 17. September startet die GeForce RTX 3080. Spätestens dann wird mit ersten Tests der Karte zu rechnen sein. Kurz darauf, am 24. September, folgt die GeForce RTX 3090.
Update: Aufbau des Ampere Streaming Multiprocessor (SM)
Im Rahmen eines GeForce RTX 30-Series Community Q&A auf Reddit hat NVIDIA einige Fragen zu den neuen Grafikkarten bzw. GPUs und Techologien beantwortet. Eine interessierte uns dabei besonders und zwar wie NVIDIA auf beispielsweise 10.496 Shadereinheiten bei der GeForce RTX 3090 kommt, wenn doch im Vorfeld immer von 5.248 die Rede war. Gleiches gilt natürlich auch für die Angaben zur GeForce RTX 3080 und GeForce RTX 3070.
Tony Tamasi, als Senior Vice President of Content und Technology bei NVIDIA gab daraufhin ein paar interessante Details preis. So wurde der Streaming Multiprocessor (SM) der Ampere-Architektur für die GeForce-Karten doch weiter angepasst, als dies zu vermuten gewesen wäre. Im Vergleich zur GA100-GPU fliegen die FP64-Einheiten raus und stattdessen kommen weitere FP32-Einheiten dazu.
"(...) the Ampere SM includes new datapath designs for FP32 and INT32 operations. One datapath in each partition consists of 16 FP32 CUDA Cores capable of executing 16 FP32 operations per clock. Another datapath consists of both 16 FP32 CUDA Cores and 16 INT32 Cores. As a result of this new design, each Ampere SM partition is capable of executing either 32 FP32 operations per clock, or 16 FP32 and 16 INT32 operations per clock. All four SM partitions combined can execute 128 FP32 operations per clock, which is double the FP32 rate of the Turing SM, or 64 FP32 and 64 INT32 operations per clock."
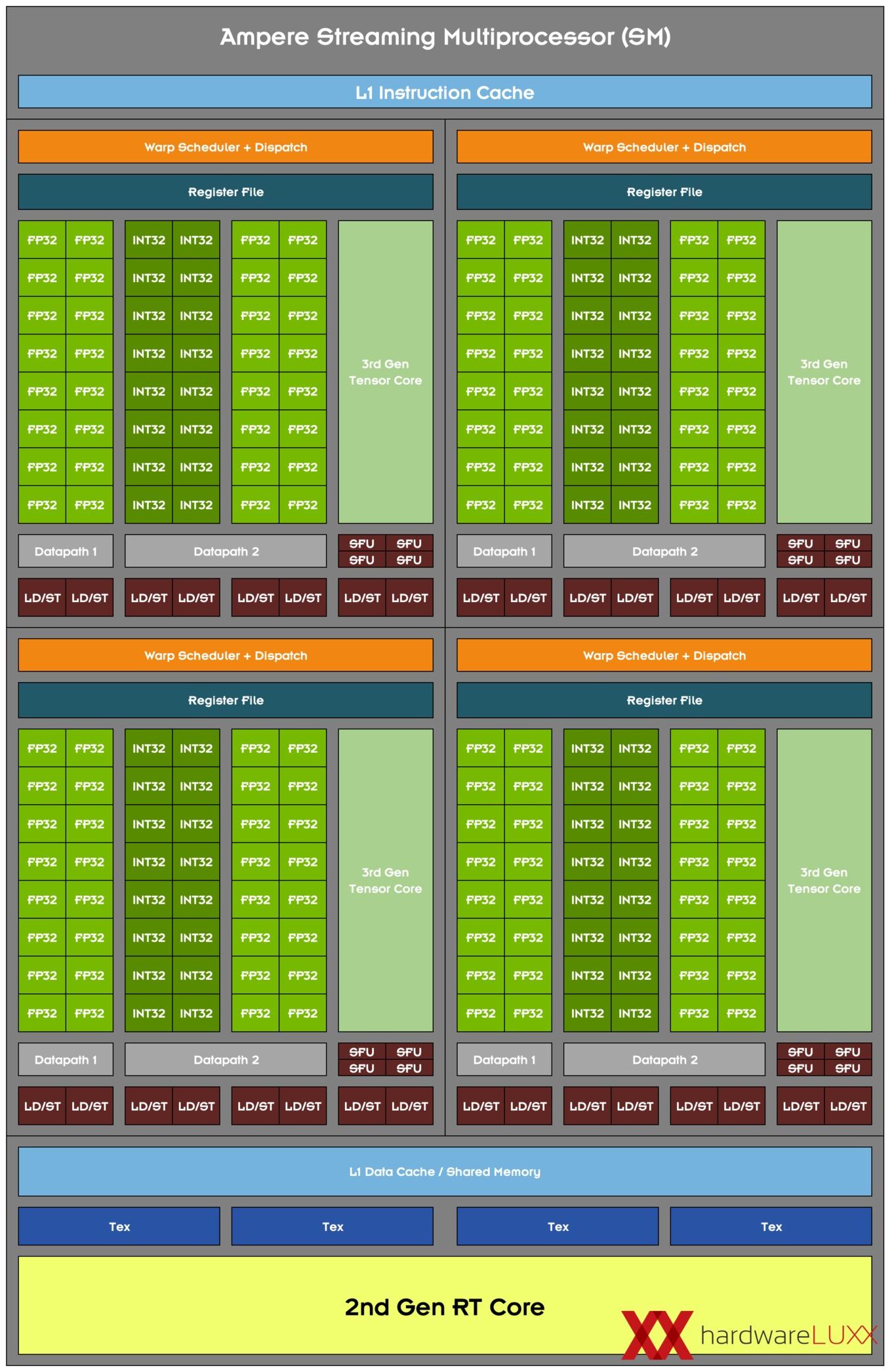
Es gibt also zwei Datenpfade, die teilweise parallel angesprochen werden können. Eine der Datenpfade besteht aus 16 FP32-Einheiten. Hier können also 16 FP32-Berechnungen pro Takt bearbeitet werden. Ein zweiter Datenpfad besteht aus jeweils 16 FP32- und INT32-Einheiten. Jeder der SM-Quadranten kann entweder 32 FP32-Operationen ausführen oder jeweils 16 FP32- und INT32-Operationen pro Takt. Für den gesamten SM bedeutet dies die mögliche Ausführung von 128 FP32-Operationen oder jeweils 64 FP32- und INT32-Operationen pro Takt.
Die Verdopplung der FP32-Recheneinheiten ist sicherlich einer der Gründe, warum die GA10x-GPUs über 28 Milliarden Transistoren verfügen. Die TU102-GPU kommt auf 18,6 Milliarden Transistoren.
Außerdem hat man den Shared Memory verdoppelt. Dies gilt auch für die Datenrate des L1-Cache. Dieser kann nun 128 Bytes pro Takt übertragen und nicht mehr nur 64 wie bei Turing. Die Gesamtdatenrate des L1-Caches steigt von 116 GB/s für eine GeForce RTX 2080 auf 219 GB/s für die GeForce RTX 3080 an.
Außerdem verkündet Tamasi, dass ein Graphics Processing Clusters (GPCs) weiterhin eine dedizierte Raster Engine beinhaltet, es nun aber zwei ROP-Partitionen mit jeweils acht ROPs gibt. Pro 32-Bit-Block des Speicherinterfaces sind also 16 ROPs verbaut und nicht mehr nur acht.
Wir wissen noch nicht, ob pro SM vier Tensor Cores verbaut sind und ob sich die Anzahl der RT Cores verändert hat. Obiges Schaubild zeigt den Ampere Streaming Multiprocessor (SM) mit vier Tensor Core pro SM (wie bei der GA100-GPU) und einen RT Core pro SM (wie bei Turing). Da die speziellen Funktionseinheiten verbessert wurde, (dritte Generation der Tensor Cores und zweite Generation der RT Cores) könnte dies durchaus so zutreffen.
