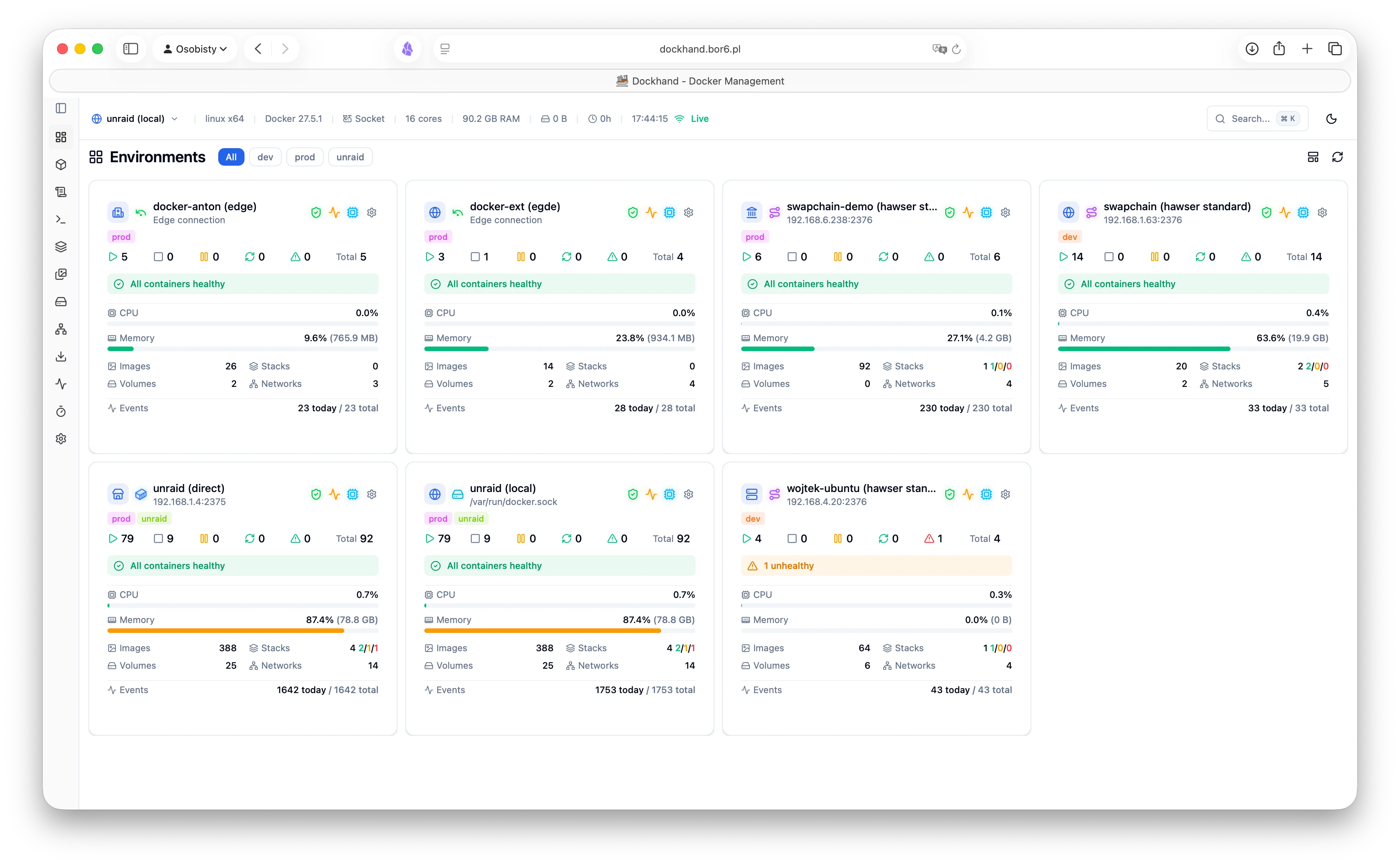
Schau dir mal Dockhand an, das hat nicht nur ein besseres GUI, sondern auch nette Features, u.a. Update Check, Remote Anbindung mit eigenem Connector und zetrale Stacks Verwaltung.
Spannend. Muss ich mir mal ansehen.
ür 16GB vRam hat das Gemma 4 26b a4b sehe gute Werte geliefert.
In dem Link existiert Gemma 4 26b a4b aber nur als "normaler" Q4 Quant:

Diese fantastische Einsparung von >50% beim "Mobile Modell" gibts hier nur bei den ganz kleinen.
Ich hab jetzt grad etwas gewühlt, ich finde kein E4B "mobile" mit ~2,5gb, ich finde nur einen Q4 Quant der ca. 3,8gb hat.
Hast du einen Link?
Fürs 26b gibts da nix "magisches"... die üblichen Unsloth Quants sind in einer ähnlichen Größe, je nach Ausführung.
Es ist aber so, dass 14,4gb "nicht" in 16gb VRAM passen, zumindest ist da kein Platz mehr für Kontext - und Kontext braucht viel, viel mehr Platz, als ich je gedacht hätte.
mEn sollte ein Modell für 16gb VRAM die 10gb nicht überschreiten, um brauchbar zu laufen...?
Ich verwende jetzt eigentlich meist Q5 Quants (ausser bei ganz kleinen Modellen Q6), im idealfall die Optimierten (XL etc., je nach dem), ist wohl meiner Recherche nach der beste Sweetspot. Q4KM ist wohl nicht schlecht absolut gesehen, beginnt aber zu Q5 schon deutlich abzunehmen (ob das nun nur in den Tests stattfindet oder real?), Q5 hingegen ist von Q6 und Q8 meist nur sehr wenig entfernt - theoretisch.
NVFP4 wäre wohl noch interessant, der Geschwindigkeit wegen, dürfte aber Nvidia only sein, insofern leider weniger interessant für den Server.
Hab eh schon kurz überlegt die 5090 in den Server zu stecken und durch eine 9070XT zu ersetzen, dann kann ich aber nimmer lokal mit img/vid rumspielen, mein Plan wär die LLM am Server zu haben und img/vid lokal. Momentan ist ne AMD AI Pro 9700 32gb für ~1450€ wohl das realistischte, dürfte wohl doch besser als die Intel sein (welche von den 950 usd uvp leider weit weg ist).
Gestern dann noch Open-WebUI zum laufen gebracht inkl. text to speach (kokoro im Docker auf CPU laufend), speach to text läuft weitgehend (whisper medium auf cpu), nur eine Funktion bugt noch (Sprachnachricht aufnehmen und senden im Browser), ist wohl ein http/https Problem, meh.
Gemma 4 12b (als Quant, Q5 oder Q6 denk ich, weiss nimmer) läuft da nun, ca. 5 token/s, was jestzt nicht ultimativ schnell ist (braucht dann 5 min für eine mittlere 1500 Token Antwort).
=> Dafür, dass der 5650G am MC12 samt RAM einfach rumgelegen ist, bin ich damit aber mehr als zufrieden, ist für mich ein toller proof of concept.
Meine Hoffnung wäre, dass die alte iGPU des Cezanne für TTS und STT schnell genug ist, dann könnte ich auf der GPU das LLM laufen lassen und auf der iGPU TTS/STT. Die Kombi würde mich sehr befriedigen.