
A100
-
Video-Dokumentation: Der blühende Schwarzmarkt für KI-Beschleuniger in China
 Gamers Nexus hat eine dreieinhalbstündige Dokumentation über den Schwarzmarkt für KI-Beschleuniger in China veröffentlicht. In der Dokumentation wird über die aktuelle Situation der Exportbeschränkungen und deren Sinnhaftigkeit berichtet, vor allem aber geht es darum, wie einfach es trotz aller Beschränkungen ist, in China an die gewünschte Hardware zu kommen. Die mehr als 200 Minuten zusammenzufassen, fällt nicht ganz leicht, denn es gibt... [mehr]
Gamers Nexus hat eine dreieinhalbstündige Dokumentation über den Schwarzmarkt für KI-Beschleuniger in China veröffentlicht. In der Dokumentation wird über die aktuelle Situation der Exportbeschränkungen und deren Sinnhaftigkeit berichtet, vor allem aber geht es darum, wie einfach es trotz aller Beschränkungen ist, in China an die gewünschte Hardware zu kommen. Die mehr als 200 Minuten zusammenzufassen, fällt nicht ganz leicht, denn es gibt... [mehr] -
MI250 gegen A100: MosaicML zeigt Konkurrenten fast auf Augenhöhe
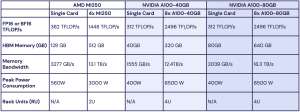 Vor einigen Wochen machte das Unternehmen MosaicML auf sich aufmerksam, da man vortrainierte MPT-7B-Modelle als Open-Source veröffentlichte und somit der LLM-Forschung (Large Language Model) einen gewissen Vortrieb geben wollte. Bei MosaicML hat man sich darauf spezialisiert, das Software-Ökosystem für AI-Systeme zu optimieren, denn über eine optimierte Software lassen sich große Leistungssprünge im Training erreichen – ein um 30 %... [mehr]
Vor einigen Wochen machte das Unternehmen MosaicML auf sich aufmerksam, da man vortrainierte MPT-7B-Modelle als Open-Source veröffentlichte und somit der LLM-Forschung (Large Language Model) einen gewissen Vortrieb geben wollte. Bei MosaicML hat man sich darauf spezialisiert, das Software-Ökosystem für AI-Systeme zu optimieren, denn über eine optimierte Software lassen sich große Leistungssprünge im Training erreichen – ein um 30 %... [mehr] -
TSMC: Erhöhte Produktion für NVIDIA macht Kapazitätsausbau notwendig
 Entgegen dem Trend waren bis zuletzt in den Auftragsbüchern von TSMC kaum Auftragslücken zu finden. Das Unternehmen ist derzeit noch gut ausgelastet und der derzeitige Boom von Künstlicher Intelligenz und High-Performance-Computing lässt sogar die Kapazitäten von TSMC an ihre Grenzen kommen. Die Nachfrage nach fortschrittlichen Prozesstechnologien führender Chiphersteller – allen voran nach Grafikprozessoren wie dem A100 und dem H100 von... [mehr]
Entgegen dem Trend waren bis zuletzt in den Auftragsbüchern von TSMC kaum Auftragslücken zu finden. Das Unternehmen ist derzeit noch gut ausgelastet und der derzeitige Boom von Künstlicher Intelligenz und High-Performance-Computing lässt sogar die Kapazitäten von TSMC an ihre Grenzen kommen. Die Nachfrage nach fortschrittlichen Prozesstechnologien führender Chiphersteller – allen voran nach Grafikprozessoren wie dem A100 und dem H100 von... [mehr] -
AMD und NVIDIA dürfen GPU-Beschleuniger nicht mehr nach China exportieren
 Von der US-Regierung sind neue Einschränkungen für den Handel mit China erlassen worden – dies berichtet Reuters unter Berufung auf Unternehmenskreise bei NVIDIA. Da die Export-Beschränkungen allerdings eine ganze Produktgruppe betreffen, ist von auszugehen, dass auch andere Hersteller ihre Produkte nicht mehr nach China exportieren dürfen. Dies beträfe dann sogar AMD und Intel. Betroffen seien aber nicht sämtliche GPU-Beschleuniger,... [mehr]
Von der US-Regierung sind neue Einschränkungen für den Handel mit China erlassen worden – dies berichtet Reuters unter Berufung auf Unternehmenskreise bei NVIDIA. Da die Export-Beschränkungen allerdings eine ganze Produktgruppe betreffen, ist von auszugehen, dass auch andere Hersteller ihre Produkte nicht mehr nach China exportieren dürfen. Dies beträfe dann sogar AMD und Intel. Betroffen seien aber nicht sämtliche GPU-Beschleuniger,... [mehr] -
NVIDIA: Referenzdesigns für HGX Grace (Hopper) und wassergekühlte A100- und H100-Karten
 Zur Computex 2022 stellt NVIDIA, genauer gesagt die Datacenter-Sparte, unter anderem die ersten Referenzdesigns für zukünftige HGX-Systeme vor und will mit wassergekühlten A100- und H100-PCIe-Karten die Effizienz der dazugehörigen Server steigern. Auf der diesjährigen GPU Technology Conference gab NVIDIA weitere Details zum Grace-CPU-Superchip bestehend aus zwei ARM-Chips mit jeweils 72 Kernen und dem Grace-Hopper-Superchip als Kombination aus... [mehr]
Zur Computex 2022 stellt NVIDIA, genauer gesagt die Datacenter-Sparte, unter anderem die ersten Referenzdesigns für zukünftige HGX-Systeme vor und will mit wassergekühlten A100- und H100-PCIe-Karten die Effizienz der dazugehörigen Server steigern. Auf der diesjährigen GPU Technology Conference gab NVIDIA weitere Details zum Grace-CPU-Superchip bestehend aus zwei ARM-Chips mit jeweils 72 Kernen und dem Grace-Hopper-Superchip als Kombination aus... [mehr] -
Bis zu 16.000 A100-GPUs: Facebook baut schnellsten AI-Supercomputer
 Meta hat ein neues AI Research SuperCluster (RSC) aufgebaut, welches nun eröffnet wurde. Das System besteht aktuell aus 760 DGX-A100-Servern, die jeweils acht A100-GPU-Beschleunigern einsetzen. Miteinander verbunden sind die GPUs über einen EPYC-Prozessor pro DGX-A100-Server. Aktuell kommen also bereits 6.080 A100-GPUs zum Einsatz. Derzeit gibt Meta die Rechenleistung mit 1,895 ExaFLOPS für Berechnungen mit einfacher Genauigkeit... [mehr]
Meta hat ein neues AI Research SuperCluster (RSC) aufgebaut, welches nun eröffnet wurde. Das System besteht aktuell aus 760 DGX-A100-Servern, die jeweils acht A100-GPU-Beschleunigern einsetzen. Miteinander verbunden sind die GPUs über einen EPYC-Prozessor pro DGX-A100-Server. Aktuell kommen also bereits 6.080 A100-GPUs zum Einsatz. Derzeit gibt Meta die Rechenleistung mit 1,895 ExaFLOPS für Berechnungen mit einfacher Genauigkeit... [mehr] -
Intel-System verspätet sich: DoE ordert weiteren Supercomputer
NVIDIA hat gemeinsam mit dem U.S. Department of Energy (DoE) einen weiteren Supercomputer angekündigt. Das Polaris getaufte System wird vermutlich noch in diesem Jahr aufgestellt und in Betrieb genommen. Eigentlich war für die Jahre 2022 und 2023 die Inbetriebnahme gleich zweier Exascale-Systeme geplant. Während der mit EPYC-Prozessoren und Radeon-Instinct-Beschleunigern ausgestattete El Capitan erst für 2023 geplant war, sollte der... [mehr] -
Aerial A100 bringt AI-on-5G, A100 PCIe bekommt 80 GB und GPUDirect Storage
NVIDIA hat eine Reihe von Ankündigungen zur ISC High Performance und dem eigentlich ebenfalls ab heute geplanten Mobile World Congress zu machen, die über die kommenden Tage in virtueller Form stattfinden werden. Einer der Bereiche, auf den sich NVIDIA zum MWC fokussiert hat, ist AI-on-5G. Viele an der 5G-Infrastruktur beteiligten Unternehmen sehen zukünftig eine tiefere Integration einer höheren Rechenleistung nahe... [mehr] -
NVIDIA verdoppelt den Speicher der A100-GPU und bietet DGX-Workstation an
Die im Frühjahr auf der GPU Technology Conference vorgestellte A100 wird um ein weiteres Modell erweitert. Die A100 80GB GPU besitzt, wie der Name schon verrät, den doppelten Speicherausbau gegenüber der vorherigen Variante und bekommt zudem den schnelleren HBM2e spendiert. Es bleibt allerdings beim GPU-Ausbau mit 108 SMs und damit 3.456 FP64- und 6.912 FP32-Recheneinheiten und auch das Speicherinterface verbleibt bei 5.120 Bit – ein... [mehr] -
MLPerf 0.7 Inferencing zeigt NVIDIAs aktuellen Vorsprung auf
MLPerf hat sich zum Ziel gesetzt, eine bessere Vergleichbarkeit für die Bestimmung und den Vergleich von Rechenleistung im AI-, bzw. ML-Bereich herzustellen. Neben den großen Chip-Herstellern Intel und NVIDIA sind auch ARM, Google, Intel, MediaTek, Microsoft und viele anderen Unternehmen daran beteiligt und ermöglichen somit eine bessere Vergleichbarkeit der Leistung in diesem Bereich. Nachdem bereits vor einiger Zeit die Resultate... [mehr] -
NVIDIA nennt MLPerf-Leistungsdaten für den A100-Beschleuniger
In Zusammenarbeit mit MLPerf hat NVIDIA nun erste Leistungsdaten des A100-Beschleunigers auf Basis der Ampere-Architektur bzw. der GA100-GPU veröffentlicht. Vorgestellt hatte man diesen auf der GPU Technology Conference Mitte Mai. Neben der Datacenter- gibt es inzwischen auch eine PCI-Express-Variante. MLPerf soll eine Vergleichbarkeit zwischen den verschiedenen Machine-Learning-Systemen ermöglichen, denn echte Benchmarks wie wir sie von... [mehr] -
NVIDIA A100 zeigt sich im ersten Workstation-Benchmark
Mitte Mai stellte NVIDIA mit dem A100 den ersten GPU-Beschleuniger auf Basis der Ampere-Architektur vor. Inzwischen hat man auch eine PCI-Express-Variante vorgestellt. Neben den von NVIDIA veröffentlichten, eher theoretischen Leistungswerten, kennen wir das wirkliche Leistungspotenzial aber noch nicht. Zumindest zu einem geringen Anteil hat sich dies nun geändert. Jules Urbach, CEO von OTOY, die unter anderem... [mehr] -
A100 PCIe: NVIDIA GA100-GPU kommt auch als PCI-Express-Variante
Mitte Mai stellte NVIDIA mit dem A100 den ersten GPU-Beschleuniger auf Basis der Ampere-Architektur vor. Die hier verwendete GA100-GPU ist mit 826 mm² und 54 Milliarden Transistoren die größte, die bisher in 7 nm gefertigt wurde. NVIDIA stößt damit gemeinsam mit dem Auftragsfertiger TSMC an die Grenzen des aktuell technisch möglichen. Bisher aber gibt es den A100-Beschleuniger nur in Form der SXM4-Module. Heute kündigt... [mehr] -
Ampere-Architektur Deep-Dive: GA100 ohne RT-Kerne und Details zum neuen NVSwitch
In einem sogenannten Deep Dive hat Jonah Alben, Senior Vice President des GPU-Engineering bei NVIDIA einige weitere Fragen und Details zur Ampere-Architektur beantwortet. Alle wichtigen Details zur Ampere-Architektur haben wir uns bereits angeschaut. Darüber hinaus haben wir uns bereits in einer Analyse damit beschäftigt, wie viel GeForce in der GA100-GPU steckt. Wer sich neue Erkenntnisse zu einer möglichen nächsten Generation der... [mehr] -
Supermicro packt A100-GPUs in seine 1U-, 2U-, 4U- und 10U-Server
Im Zuge der heutigen Präsentation der A100-GPU bzw. der Ampere-Architektur durch NVIDIA stellt auch Supermicro also einer der engsten Partner von NVIDIA seine neuen bzw. aktualisierten Produkte vor. Mit der Ampere-Architektur passt NVIDIA seine GPGPU derart an, dass sie einen breiteren Anwendungsbereich im Datacenter abdecken kann. Sowohl das Training, also auch das Inferencing von AI-Modellen, aber auch HPC-Anwendungen. NVIDIA selbst sprach... [mehr] -
GA100: 7 nm, 54 Milliarden Transistoren – NVIDIA präsentiert die Ampere-Architektur
NVIDIA hat auf der virtuellen Keynote der GPU Technology Conference die Katze aus dem Sack gelassen und die Ampere-Architektur vorgestellt. Noch kennen wir nicht alle Details, aber wir kennen einige Eckdaten der neu vorgestellten Produkte. Nach der Vorstellung der Volta-Architektur vor drei Jahren, stellt NVIDIA nun den Nachfolger vor. Die Ampere-Architektur wurde im Hinblick auf drei Ziele entwickelt: Die Leistung sollte signifikant... [mehr]
