
Werbung
In guter alter Tradition stand auf der Pressekonferenz von NVIDIA die Vorstellung einer neuen Tegra-Generation an. Bereits im Frühjahr 2014 wurden auf der hauseigenen Messe GTC 2014 die Weichen für Erista gestellt. Dabei sollte es sich um einen SoC handeln, der wie der Tegra K1 ein GPU-Cluster der Desktop-Architektur verwendet, dabei aber auf die neue "Maxwell"-Generation setzt. Der letztendliche Produktname Tegra X1 lässt anders als der Tegra K1 aber nichts von der "Maxwell"-Architektur durchscheinen und es wird wohl auch noch einige Zeit dauern, bis wir erste Produkte mit dem neuen Chip sehen werden.

Seine Rechenleistung bezieht der Tegra X1 aus acht ARM-CPU-Kernen. Verwendet werden dabei jeweils vier ARM-Kerne im Cortex-A57- und Cortex A-53-Design. NVIDIA scheint also auf das big.LITTLE-Konzept von ARM zu wechseln, bei dem vier leistungsstarke Kerne von vier sparsameren ergänzt werden und je nach Anwendung und Bedarfsfall zwischen diesen gewechselt wird. Der Tegra K1 war und ist noch in einer Version verfügbar, die einen Companion-Core für die weniger aufwendigen Berechnungen vorsieht und dabei die hungrigeren Kerne pausieren lässt. Was aus dem Projekt-"Denver" und den daraus entwickelten CPU-Kernen geworden ist, die bei einer Variante des Tegra K1 zum Einsatz kommen, ist unklar. Weiterhin zum Einsatz kommt das erwähnte "Maxwell"-GPU-Cluster mit seinen 256 Shadereinheiten. Zusammengenommen erreichen diese beiden Komponenten eine Rechenleistung von 1 TFLOP und ermöglichen beispielsweise das Abspielen von 4K Videoinhalten mit 60 Bildern die Sekunde. Noch beeindruckender war allerdings die Demo der Unreal Engine 4. Genauer gesagt wurde die Elemental-Demo auf dem Tegra X1 gezeigt. Die Leistungsaufnahme des Chips soll dabei 10 Watt betragen haben - gefertigt wird er im 20-nm-Prozess. Zum Vergleich herangezogen wird die Tatsache, dass eine Xbox One dafür rund 100 Watt benötigt und eine Grafikkarten von NVIDIA vor rund zwei Jahren noch etwa 300 Watt benötigte. Allerdings soll die Elemental-Demo auf dem Tegra X1 auch einige Partikel-Effekte vermissen lassen - so der Eindruck des Publikums vor Ort.

Für einen weiteren Vergleich wurde ein 15 Jahre alter Supercomputer namens ASCI Red herangezogen. Der vom U.S. Department of Energy's Sandia National Laboratory betriebene Supercomputer belegte eine Fläche von 1.600 Quadratfuß und verbrauchte 500.000 Watt an Leistung. Weitere 500.000 Watt wurden benötigt um den Raum, in dem er stand, zu kühlen. Der Tegra X1 erreicht die bereits angesprochenen 1 TFLOP mit der Größe eines Fingernagels und der Leistungsaufnahme von nur 10 Watt.
Das Einsatzgebiet des Tegra X1 ist klar umrissen: NVIDIA will weiterhin den Tablet-Markt bedienen, richtet seinen Fokus aber ebenfalls auf die Automobilindustrie. Der Tegra X1 muss dazu aber nicht nur beweisen, dass er bei maximaler Performance möglichst effizient ist, sondern im Alltagsbetrieb auch stromsparend zu Werke geht. Diesen Nachweis blieb NVIDIA zu einem solch frühen Zeitpunkt der Produktentwicklung noch aus. Seit Jahren versucht NVIDIA mehr und mehr Marktanteile für Tablet-SoCs an sich zu reißen, bisher ist es aber bei einem niedrigen einstelligen Prozentsatz geblieben. In Sachen Schnittstellen und APIs ist man bereits für das Jahr 2015 und darüber hinaus gerüstet. Unterstützt werden DirectX 12, OpenGL 4.5, CUDA, OpenGL ES 3.1 und auch das Android Extension Pack ist bereits verfügbar.
Update:
Inzwischen konnten wir mehr Details zum Tegra X1 in Erfahrung bringen. So verwendet dieser jeweils 2x vier unterschiedliche CPU-Kerne, aber nicht das big.LITTLE-Konzept von ARM. Es wird ein eigener Interconnect und nicht der ARM CCI-400 verwendet. Anstatt auf ein 2x4-Core-Cluster können die Tasks auf alle acht Kerne verteilt werden. Den Programmierern und damit letztendlich auch den Apps stehen also alle acht Kerne zur Verfügung. Die vier A57-Kerne verwenden dabei einen gemeinsamen 2 MB großen L2-Cache sowie pro Kern 48 bzw. 32 KByte an L1-Cache (Instruction- und Data-Cache). Das A53-Cluster muss mit 512 KByte an L2-Cache für alle vier Kerne auskommen. Hier stehen jeweils 32 KByte an L1-Cache für Instruktionen und Daten zur Verfügung.

Auch die Frage warum NVIDIA nicht die eigenen "Denver"-Kerne einsetzt, konnte inzwischen beantwortet werden. Mit den beiden A57- und A53-Clustern sei es schneller möglich gewesen den Tegra X1 auf den Markt zu bringen, als es mit den "Denver"-Kernen möglich gewesen wäre. Das Projekt-"Denver" könnte aber bei der nächsten Generation des Tegra-SoC "Parker" wieder eine Rolle spielen.
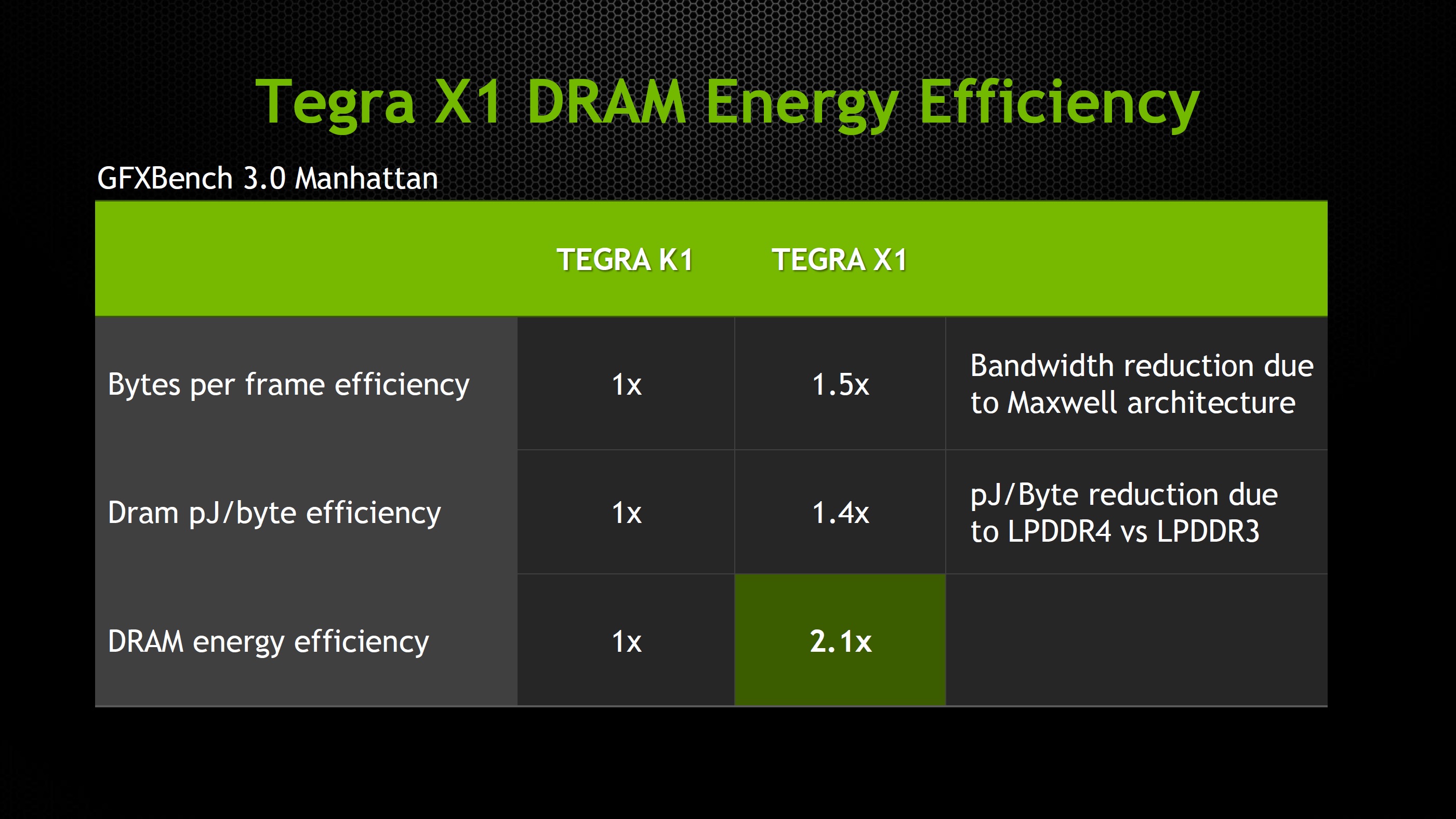
Auch außerhalb der CPU und GPU des Tegra X1 gibt es noch einige Änderungen. So wechselt NVIDIA vom 64 Bit LPDDR3 auf einen 64 Bit LPDDR4-Speicher und beschleunigt damit die Speicherbandbreite von 14,9 auf 25,6 GB pro Sekunde. Damit wird letztendlich auch das Video-Encoding in 4K bei 60 Bildern pro Sekunde ermöglicht. Profitieren können davon natürlich auch grafikintensive Anwendungen. Auf Seiten der Anschlüsse für Displays kommt nun auch HDMI 2.0 hinzu, damit eine solche Auflösung bei dieser Bildwiederholungsrate auch ausgegeben werden kann.
Mit der "Maxwell"-Architektur arbeiten Desktop und Mobile enger zusammen, als bisher. Features wie die Speicherkompression kommen auch dem Tegra X1 mit dem nur 64 Bit breiten Speicherinterface zu Gute. Gleiches gilt auch für die Effizienz der "Maxwell"-Architektur. Aber es gibt auch einige Features bei "Maxwell", die sich bisher nur im Tegra X1 wiederfinden.

Dazu gehört der sogenannte "Double Speed FP16"-Support. Wie die "Fermi"- und "Kepler"-Architektur zuvor auch, bietet "Maxwell" dedizierte FP32- und FP64-CUDA-Kerne. Dies ist auch beim "Maxwell"-Cluster auf dem Tegra X1 so. Allerdings spielen in diesem Segment FP16-Berechnungen eine wesentlich größere Rolle. NVIDIA hat also das Handling dieser FP16-Berechnungen geändert, um von den dedizierten FP32-Kernen profitieren zu können. Dazu werden FP16-Berechnungen zusammengelegt, damit sie auf FP32-Kernen ausgeführt werden können. Damit die FP16-Berechnungen zusammengelegt werden können, müssen sie allerdings die gleichen Operationen ausführen. Zum Beispiel können nur zwei Additionen oder zwei Multiplikationen zusammengeführt werden. FP16-Operationen sind für die Ausführung von Android ebenso entscheidend wie bei Spielen oder der Analyse von Foto- und Videodaten. Die Konkurrenz von ARM, Imagination Technology und AMD hat dies bereits vor einiger Zeit erkannt. NVIDIA legt beim Tegra X1 nun auch wieder deutlich mehr Wert darauf und will daher in Sachen Performance einen Schritt nach Vorne machen.
| NVIDIA Tegra K1 und Tegra X1 im Vergleich | ||
|---|---|---|
| Modell | Tegra K1 | Tegra X1 |
| Technische Daten | ||
| Architektur | Kepler | Maxwell |
| Fertigung | TSMC 28 nm | TSMC 20 nm |
| Shadereinheiten | 192 | 256 |
| Textureinheiten | 8 | 16 |
| ROPs | 4 | 16 |
| GPU-Takt | etwa 950 MHz | etwa 1.000 MHz |
| Speicher-Takt | 930 MHz | 1.600 MHz |
| Speichertyp | LPDDR3 | LPDDR4 |
| Speicherbandbreite | 64 Bit | 64 Bit |
| FP16-Performance | 365 GFLOPS | 1.024 GFLOPS |
| FP32-Performance | 365 GFLOPS | 512 GFLOPS |
Datenschutzhinweis für Youtube
An dieser Stelle möchten wir Ihnen ein Youtube-Video zeigen. Ihre Daten zu schützen, liegt uns aber am Herzen: Youtube setzt durch das Einbinden und Abspielen Cookies auf ihrem Rechner, mit welchen Sie eventuell getracked werden können. Wenn Sie dies zulassen möchten, klicken Sie einfach auf den Play-Button. Das Video wird anschließend geladen und danach abgespielt.
Ihr Hardwareluxx-Team
Youtube Videos ab jetzt direkt anzeigen
