
Inferencing
-
Tensordyne Napier: Inferencing-Angriff auf NVIDIA, Google und Co
 Mit neuen Datenformaten und einer auf diese abgestimmten Hardware will Tensordyne den etablierten KI-Hardwareanbietern Konkurrenz machen. Mathematische Optimierungen wie Sparsity sowie der Einsatz kompakter Datenformate wie FP8 oder FP4 im KI-Inferencing steigern durch eine stärkere Komprimierung die Rechenleistung und Energieeffizienz, ohne die Genauigkeit der Modelle nennenswert zu beeinträchtigen. Einen weiteren Ansatz verfolgt Tensordyne... [mehr]
Mit neuen Datenformaten und einer auf diese abgestimmten Hardware will Tensordyne den etablierten KI-Hardwareanbietern Konkurrenz machen. Mathematische Optimierungen wie Sparsity sowie der Einsatz kompakter Datenformate wie FP8 oder FP4 im KI-Inferencing steigern durch eine stärkere Komprimierung die Rechenleistung und Energieeffizienz, ohne die Genauigkeit der Modelle nennenswert zu beeinträchtigen. Einen weiteren Ansatz verfolgt Tensordyne... [mehr] -
Computex 2026: Qualcomm will überall Tokens verarbeiten und zeigt Serverplattform Dragonfly
 Qualcomm hatte auf seiner Keynote der Computex wenig Hardware-Neuigkeiten mitgebracht. Bereits vor einer Woche vorgestellt wurde die Snapdragon-C-Plattform für günstige Notebooks, die später dieses Jahres mit allen Details enthüllt werden soll. Einige Wochen vor dem eigenen Investors Day wollte man aber dennoch etwas zu verkünden haben. Zumindest namentlich genannt wurde die kommende Serverplattform mit der eigenen AI200- und... [mehr]
Qualcomm hatte auf seiner Keynote der Computex wenig Hardware-Neuigkeiten mitgebracht. Bereits vor einer Woche vorgestellt wurde die Snapdragon-C-Plattform für günstige Notebooks, die später dieses Jahres mit allen Details enthüllt werden soll. Einige Wochen vor dem eigenen Investors Day wollte man aber dennoch etwas zu verkünden haben. Zumindest namentlich genannt wurde die kommende Serverplattform mit der eigenen AI200- und... [mehr] -
Crescent Island: PCB von Intels PCIe-Inference-Beschleuniger mit 20 LPDDR5X-Chips zeigt sich
 Im Oktober 2025 kündigte Intel mit Crescent Island eine neue Datacenter-GPU auf Basis der Xe3P-Architektur mit 160 GB LPDDR5X an. In der zweiten Jahreshälfte dieses Jahres will Intel damit neben den Xeon-Prozessoren auch bei den KI-Beschleunigern wieder mitspielen. Nun sind Fotos der Vor- und Rückseite des PCBs aufgetaucht. Diese zeigen den Platz für das riesige GPU-Package, nebst Platz für die Strom- und Spannungsversorgung und das... [mehr]
Im Oktober 2025 kündigte Intel mit Crescent Island eine neue Datacenter-GPU auf Basis der Xe3P-Architektur mit 160 GB LPDDR5X an. In der zweiten Jahreshälfte dieses Jahres will Intel damit neben den Xeon-Prozessoren auch bei den KI-Beschleunigern wieder mitspielen. Nun sind Fotos der Vor- und Rückseite des PCBs aufgetaucht. Diese zeigen den Platz für das riesige GPU-Package, nebst Platz für die Strom- und Spannungsversorgung und das... [mehr] -
CPU-Boom um Agentic AI: NVIDIA liefert die ersten Vera-CPUs aus
 Auf den noch immer anhaltenden Boom bei den KI-Beschleunigern folgen nun die Prozessoren, die eine immer größere Nachfrage erfahren. Davon profitieren besonders AMD und Intel, aber auch die Hyperscaler wie AWS, Microsoft und Google haben mit den eigenen CPUs offenbar auf das richtige Pferd gesetzt. Auch bei NVIDIA hat man längst erkannt, dass ein Serverprozessor mehr als nur ein Host für die KI-Beschleuniger ist. Mit der... [mehr]
Auf den noch immer anhaltenden Boom bei den KI-Beschleunigern folgen nun die Prozessoren, die eine immer größere Nachfrage erfahren. Davon profitieren besonders AMD und Intel, aber auch die Hyperscaler wie AWS, Microsoft und Google haben mit den eigenen CPUs offenbar auf das richtige Pferd gesetzt. Auch bei NVIDIA hat man längst erkannt, dass ein Serverprozessor mehr als nur ein Host für die KI-Beschleuniger ist. Mit der... [mehr] -
MLPerf 6.0 Inference: Alle Hersteller proklamieren Gewinne für sich
 Gestern wurden die neuen Benchmarks des MLPerf Inference in der Version 6.0 veröffentlicht. Im Hinblick auf die verwendeten KI-Chips teilgenommen haben AMD, Intel und NVIDIA – allerdings in unterschiedlicher Ausbaugröße. NVIDIA fokussiert sich auf besonders große Cluster mit bis zu 72 Blackwell-Chips in einem Rack für ein möglichst effizientes Inferencing von KI-Modellen. Damit will man vorrangig ein kosteneffizientes Inferencing... [mehr]
Gestern wurden die neuen Benchmarks des MLPerf Inference in der Version 6.0 veröffentlicht. Im Hinblick auf die verwendeten KI-Chips teilgenommen haben AMD, Intel und NVIDIA – allerdings in unterschiedlicher Ausbaugröße. NVIDIA fokussiert sich auf besonders große Cluster mit bis zu 72 Blackwell-Chips in einem Rack für ein möglichst effizientes Inferencing von KI-Modellen. Damit will man vorrangig ein kosteneffizientes Inferencing... [mehr] -
GTC 2026: AMD kontert NVIDIAs Inference-Versprechen
 Seit einigen Monaten zeichnet sich ab, dass das Training neuer KI-Modelle zwar weiterhin ein zentrales Einsatzfeld für KI-Beschleuniger bleibt, künftig aber zunehmend auch die effiziente Bereitstellung dieser Modelle als Services im Vordergrund stehen wird. Dafür lassen sich einerseits bestehende Beschleuniger auf Basis der Blackwell- oder Rubin-Architektur einsetzen. Noch effizienter gelingt das Inferencing jedoch mit speziell angepasster... [mehr]
Seit einigen Monaten zeichnet sich ab, dass das Training neuer KI-Modelle zwar weiterhin ein zentrales Einsatzfeld für KI-Beschleuniger bleibt, künftig aber zunehmend auch die effiziente Bereitstellung dieser Modelle als Services im Vordergrund stehen wird. Dafür lassen sich einerseits bestehende Beschleuniger auf Basis der Blackwell- oder Rubin-Architektur einsetzen. Noch effizienter gelingt das Inferencing jedoch mit speziell angepasster... [mehr] -
GTC 2026: NVIDIA kündigt das Vera-CPU-Rack für CPU-only Inferencing an
 Bisher waren die CPU-Eigenentwicklungen von NVIDIA in Form der Grace-CPUs nur das Beiwerk zu den GPU-Beschleunigern und dienten primär als Host für die Rechenknoten. Theoretisch aber hatte NVIDIA schon mit der Grace-CPU ein weitaus breiteres Anwendungsfeld ins Auge gefasst. Mit der Vera-CPU will man dies nun endlich umsetzen. Meta hat als einer der größten Hyperscaler bereits angekündigt, dass man CPU-only Vera-Racks in seinen Rechenzentren... [mehr]
Bisher waren die CPU-Eigenentwicklungen von NVIDIA in Form der Grace-CPUs nur das Beiwerk zu den GPU-Beschleunigern und dienten primär als Host für die Rechenknoten. Theoretisch aber hatte NVIDIA schon mit der Grace-CPU ein weitaus breiteres Anwendungsfeld ins Auge gefasst. Mit der Vera-CPU will man dies nun endlich umsetzen. Meta hat als einer der größten Hyperscaler bereits angekündigt, dass man CPU-only Vera-Racks in seinen Rechenzentren... [mehr] -
Leistungs- und TCO-Einschätzung: SemiAnalysis wiederholt Benchmarks täglich
Die Analysten von SemiAnalysis haben in Zusammenarbeit mit AMD, NVIDIA, Microsoft, OpenAI, Together AI, CoreWeave, Nebius, PyTorch Foundation, Supermicro, Crusoe, HPE, Tensorwave, VLLM, SGLang und einigen mehr ein neues Open-Source-Werkzeug entwickelt, welches die Inferencing-Leistung der aktuellen Hardware beleuchten soll. InferenceMAX lautet der Name der Vergleichs-Plattform. Tokens pro Sekunde, Tokens je GPU, Tokens pro Watt, aber auch... [mehr] -
Google TPU Ironwood: Google bereitet sich auf den Inferencing-Boom vor
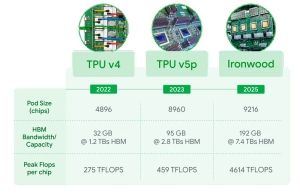 Auf der Google Cloud Next 25 hat der Internetriese Google oder besser die Cloud-Sparte die nächste Generation seiner eigenen Tensor Processing Unit (TPU) präsentiert. Der Ironwood genannte Prozessor bietet eine Spitzen-Rechenleistung von 4.614 TFLOPs an FP8-Rechenleistung. Nach NVIDIA und AMD richtet Google die eigene Hardware klar auf das Inferencing von KI-Modellen aus. Die Hardware kommt also weniger für das Training neuer Modelle zum... [mehr]
Auf der Google Cloud Next 25 hat der Internetriese Google oder besser die Cloud-Sparte die nächste Generation seiner eigenen Tensor Processing Unit (TPU) präsentiert. Der Ironwood genannte Prozessor bietet eine Spitzen-Rechenleistung von 4.614 TFLOPs an FP8-Rechenleistung. Nach NVIDIA und AMD richtet Google die eigene Hardware klar auf das Inferencing von KI-Modellen aus. Die Hardware kommt also weniger für das Training neuer Modelle zum... [mehr] -
MTIAv2: Meta präsentiert die nächste Generation seines eigenen Inferencing-Chips
 Meta hat die zweite Generation seines MTIA (Meta Training and Inference Accelerator) präsentiert. Erst Anfang Februar hatte ma verkündet, dass der MTIAv2 in die eigenen Rechenzentren wandert, nun nennt man technische Details. Je nach Datentyp hat Meta die Rechenleistung des MTIA vervierfacht. Gefertigt wird der neue Chip in 5 nm bei TSMC. Die 2,35 Milliarden Transistoren kommen auf eine Chipfläche von 25,6 x 16,4 mm... [mehr]
Meta hat die zweite Generation seines MTIA (Meta Training and Inference Accelerator) präsentiert. Erst Anfang Februar hatte ma verkündet, dass der MTIAv2 in die eigenen Rechenzentren wandert, nun nennt man technische Details. Je nach Datentyp hat Meta die Rechenleistung des MTIA vervierfacht. Gefertigt wird der neue Chip in 5 nm bei TSMC. Die 2,35 Milliarden Transistoren kommen auf eine Chipfläche von 25,6 x 16,4 mm... [mehr] -
MLPerf 0.7 Inferencing zeigt NVIDIAs aktuellen Vorsprung auf
MLPerf hat sich zum Ziel gesetzt, eine bessere Vergleichbarkeit für die Bestimmung und den Vergleich von Rechenleistung im AI-, bzw. ML-Bereich herzustellen. Neben den großen Chip-Herstellern Intel und NVIDIA sind auch ARM, Google, Intel, MediaTek, Microsoft und viele anderen Unternehmen daran beteiligt und ermöglichen somit eine bessere Vergleichbarkeit der Leistung in diesem Bereich. Nachdem bereits vor einiger Zeit die Resultate... [mehr]
