Die ist ja schon im ersten Teil voller Fehler, denn ich habe oft genug darauf hingewiesen, dass Nova Lake aus vielen Tiles besteht die in unterschiedlichen Prozessen gefertigt werden und es daher viele Tape Outs gibt, ich mich aber auf die CPU Tiles der Desktop CPUs konzentriere. Und natürlich ist es nicht belegt, dass N2 nicht für Desktop CPU passt, es gibt ja noch keinen einzigen Chip aus der N2 Fertigung zu kaufen, der irgendwas belegen oder widerlegen könnte. Aber was braucht man bei einer Desktop CPU und ich meine keine kleinen Celeron, sondern schon die Topmodelle? Takt und noch mehr Takt und den bekommt man eben nicht gleich am Anfang eines neuen Prozesses, dazu braucht es Zeit um den Prozess weiterzuentwickeln, was w0mbat bestreitet, der Roadmap für Fantasie hält. Dies alles ist ChartGPT entgangen oder du hast es nicht eingegeben, deshalb habe ich ab da nicht mehr weiter gelesen, KI ist eben Blödsinn und du sollte es weniger verwenden, sondern mehr selbst zu denken.
Intel hat ja LNL und ARL nicht aus Spaß bei TSMC fertigen lassen, sondern weil sie keine andere Wahl hatten.
Weil sie damals 5 neue Prozesse in 4 Jahren gebracht haben, was den einzelnen Prozessen nicht die Zeit zum Reifen für hohe Taktraten lässt und dazu die Frage aufwirft, wie viele Kapazität man für sie ausbauen soll. Dann wurde 20A auch noch gestrichen, weil 18A so weit war, dass es sich nicht gelohnt hat mit 20A weiterzumachen. Aber 18A soll langfristig im Programm bleiben und Intel wird daher mehr Kapazität dafür aufbauen.
Bei PTL sieht man wieder eine teilweise Rückkehr zu IFS, das compute tile is immer 18A und das kleine GPU tile is Intel 3. Das plattform controller tile ist aber immer N6 und die große GPU weiterhin N3E.
Die Plattform Tile interessiert doch am Ende nicht, sondern nur die Compute Tile und selbst die iGPU ist mir recht egal, solange eine vorhanden ist, da ich kein Gamer bin und sie nur für den Desktop und YT Videos brauche.
Was möglich ist, dass es eine NVL-S Variante gibt, die in 18A kommt, zB eine mit weniger Kernen. Aber die Indizien für eine N2 Variante sind einfach zu groß.
Umgekehrt, N2 Compute Tiles sind wenn, dann für kleine Modelle mit weniger Takt, z.B. in mobilen CPUs relevant, wo die Effizienz bei moderaten Taktraten wichtiger ist als der maximale Takt, wie es eben auch bei GPU oder Smartphone SoCs der Fall ist. Da glänzt N2, aber beim maximalen Takt ist 18A-P besser.
LNL und PTL sind auf jeden Fall die besten Intel-Chips der letzten Jahre, meine Favoriten sozusagen.
Die interessieren mich weniger, ich schaue auf die Desktop CPUs und brauche für meine Anwendungen viel Multithreadperformance und auch viel RAM, da kann ich mit solchen mobilen Low-Power CPUs wenig anfangen.
Gemini ist da Skeptischer als du.
Es gibt noch keinerlei Benchmarks mit denen ein LLM trainiert worden sein könnte, wie soll da was sinnvolles bei herauskommen? Die KI ist keine Glaskugel und kann auch nicht denken oder Zusammenhänge verstehen, sondern saugt alles aus dem Internet, auch den Mist und die wildesten Behauptungen und gibt dann aus, was aufgrund der Frage die wahrscheinlichste Antwort zu sein scheint, gerne mit Halluzinationen oben drauf. Höre endlich auf die KI zu befragen, dies bringt für künftige Hardware gar nichts!
Zumal zu Produkten die noch nicht existieren und niemand zuverlässig etwas zu sagen kann....
Und dann kommst du, nach einer Antwort immer und immer wieder mit "...aber KI sagt" um die Ecke... Was genau ist eigentlich der Sinn dahinter?
Eben, die KI kann nichts wissen, was nicht schon im Internet offen steht und da stehen nur Gerüchte und Spekulationen drin, aber keine echten Benchmarks. Die muss man abwarten, dann weiß man was an den Gerüchten und Spekulationen dran war.
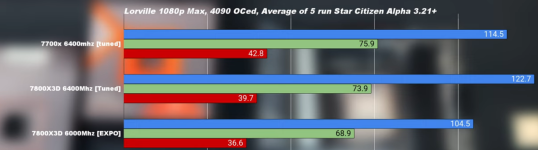
Weil das Spiel halt alle Kerne belastet und viel mehr Bandbreite benötigt als alle anderen Spiele.
Daher wohl auch die 32% unterschied zwischen 8000mhz bei 285K vs 285K mit 5600mhz bei dem Spiel.
Dann nimm halt eine HEDT Plattform die viel mehr RAM Channels und damit Bandbreite hat, denn mehr Kerne werden sonst ja nur die Leistungsaufnahme steigern, aber die fps kaum oder gar nicht verbessern, wenn vom RAM keine Daten bekommen. Ist aber eben nur ein Einzelfall und nicht pauschal auf alle Spiele oder Anwendungen übertragbar.
Aber er ist doch im Diskurs mit Holt und bringt Argumente
Was für Argumente bringt er denn? Er bringt Links zu irgendwelchen Gerüchten, meist von MLID, der schlimmsten Fakenewsschleuder im Internet oder was die KI sagt. Auf meine Argumente, z.B. das N2 eben nicht so viel Takt schaffen wird wie man es bei einer guten Desktop CPU haben will, sondern diese Taktraten erst später mit N2P und erst Recht N2X erreichbar sind, geht es nicht ein. w0mbat ebenso nicht, der meint ja, wenn der Kunde es will, könne er N2X schon heute haben, es wäre nur eine Frage des Preises.
Die Ai nutzte ich um meine neugierde zu befriedigen, aber die Ai Antwort alleine war mir nicht genug, daher fragte ich Wombat nach seiner Expertise.
Woher soll er oder sonst jemand das wissen? Die haben auch alle noch keine Nova Lake CPU.
Der mehrtakt skalierte extrem schlecht, weil die CPU auf Daten vom Ram gewartet hat, sie war quasi zu schnell für den Ram und verhungerte.
So stieg der Takt (und Abwärme und Stromverbrauch) aber viele Taktzyklen liefen ins leere weil der Ram überfordert war genug Daten zu liefern.
Wenn dein Spiel so massiv von der RAM Bandbreite abhängt, weil es am RAM Limit hängt, dann wird das bei Nova Lake nicht anderes sein und mehr Takt und mehr Kerne nur zu mehr Leistungsaufnahme führen. Außer wenn der Cache dann zufällig so groß ist, dass er mehr RAM Zugriffe abfangen kann als bei den X3D Modellen von AMD. Das hängt halt davon ab auf welche Datenmenge regelmäßig zugegriffen wird, denn Cache nutzt ja nur bei wiederholten Zugriffen und nur, wenn die Daten eben vorher nicht schon wieder verdrängt wurden.





")