
Inference
-
Crescent Island: Details zu Intels kommenden Datacenter-GPU mit 480 GB LPDDR5X auf Basis von Xe3P
 Eine Ankündigung im Oktober 2025 und eine News zu einem offenbar finalen PCB-Design von Crescent Island machten bereits die Runde. Zur Computex 2026 nennt Intel einige weitere Details zur Datacenter-GPU, mit der Intel nun auch ein größeres Stück vom KI-Kuchen abhaben möchte. Bisher sprach Intel von einer Speicherkapazität von 160 GB an LPDD5X. Nun ist die Rede von bis zu 480 GB, was sich aber auch auf die Zusammenschaltung von mehreren... [mehr]
Eine Ankündigung im Oktober 2025 und eine News zu einem offenbar finalen PCB-Design von Crescent Island machten bereits die Runde. Zur Computex 2026 nennt Intel einige weitere Details zur Datacenter-GPU, mit der Intel nun auch ein größeres Stück vom KI-Kuchen abhaben möchte. Bisher sprach Intel von einer Speicherkapazität von 160 GB an LPDD5X. Nun ist die Rede von bis zu 480 GB, was sich aber auch auf die Zusammenschaltung von mehreren... [mehr] -
VSORA Jotunn8 auf dem Cloudfest: Inference-Chip aus Frankreich soll Blackwell die Stirn bieten
 Neben weiteren Details zur Fertigung der Chips, dem Packaging und der zukünftigen Entwicklung beim Custom-HBM hat TSMC auf dem Open Innovation Platform Ecosystem Forum im vergangenen Jahr einen seiner europäischen Partner VSORA über seine Arbeit an einem Inference-Beschleuniger sprechen lassen. Ziel war es aufzuzeigen, dass es nicht nur AMD, NVIDIA und anderen Kunden von TSMC möglich ist, neue und komplexe Packages herstellen zu... [mehr]
Neben weiteren Details zur Fertigung der Chips, dem Packaging und der zukünftigen Entwicklung beim Custom-HBM hat TSMC auf dem Open Innovation Platform Ecosystem Forum im vergangenen Jahr einen seiner europäischen Partner VSORA über seine Arbeit an einem Inference-Beschleuniger sprechen lassen. Ziel war es aufzuzeigen, dass es nicht nur AMD, NVIDIA und anderen Kunden von TSMC möglich ist, neue und komplexe Packages herstellen zu... [mehr] -
Für 20 Milliarden US-Dollar: NVIDIA kauft Inference-Spezialisten Groq
 Kurz vor Weihnachten machte sich NVIDIA den Inferencing-Spezialisten Groq selbst zum Geschenk gemacht und das Start-up für 20 Milliarden US-Dollar übernommen. Groq soll als Marke wohl unabhängig bleiben, wird aber dennoch nicht mehr als eine Hülle und ein Markenname bleiben, denn neben Groqs CEO Jonathan Ross sollen auch viele Mitarbeiter zu NVIDIA wechseln. Bisher gilt der Kauf des Netzwerk-Spezialisten Mellanox für etwa 7 Milliarden als... [mehr]
Kurz vor Weihnachten machte sich NVIDIA den Inferencing-Spezialisten Groq selbst zum Geschenk gemacht und das Start-up für 20 Milliarden US-Dollar übernommen. Groq soll als Marke wohl unabhängig bleiben, wird aber dennoch nicht mehr als eine Hülle und ein Markenname bleiben, denn neben Groqs CEO Jonathan Ross sollen auch viele Mitarbeiter zu NVIDIA wechseln. Bisher gilt der Kauf des Netzwerk-Spezialisten Mellanox für etwa 7 Milliarden als... [mehr] -
MLPerf Inference 5.1: GB300, MI355X und Arc B60 erstmals mit dabei
 Die MLCommons hat heute die nächste Testrunde für Inferencing-Benchmarks in Version 5.1 gestartet und dabei spannende Leistungsdaten zu modernen KI-Beschleunigern veröffentlicht. Als neutrale Organisation kann sie in Kooperation mit den Herstellern oft verlässlichere Ergebnisse bereitstellen, als es die Unternehmen selbst gewöhnlich tun. In den MLPerf-Inference-5.0-Ergebnissen erstmals geführt wurden die Beschleuniger B200 und GB200 von... [mehr]
Die MLCommons hat heute die nächste Testrunde für Inferencing-Benchmarks in Version 5.1 gestartet und dabei spannende Leistungsdaten zu modernen KI-Beschleunigern veröffentlicht. Als neutrale Organisation kann sie in Kooperation mit den Herstellern oft verlässlichere Ergebnisse bereitstellen, als es die Unternehmen selbst gewöhnlich tun. In den MLPerf-Inference-5.0-Ergebnissen erstmals geführt wurden die Beschleuniger B200 und GB200 von... [mehr] -
MLPerf Inference 4.0: Das Debüt der H200 von NVIDIA gelingt
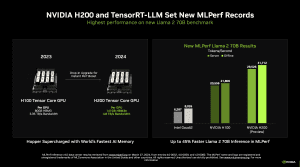 Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr]
Die MLCommons, ein Konsortium verschiedener Hersteller, welches es zum Ziel hat, möglichst unabhängige und vergleichbare Benchmarks zu Datacenter-Hardware anzubieten, hat die Ergebnisse der Inference-Runde 4.0 veröffentlicht. Darin ihr Debüt feiert der H200-Beschleuniger von NVIDIA, der zwar ebenfalls auf der Hopper-Architektur und der gleichen Ausbaustufe wie der H200-Beschleuniger von NVIDIA basiert, der aber anstatt 80 GB an HBM2 auf 141 GB... [mehr] -
Artemis: Meta bringt eigenen Inference-Chip in die Rechenzentren
 Eigentlich bereits für 2022 geplant, hat Meta nun damit begonnen, eine eigene Inferencing-Hardware in den Rechenzentren zu verbauen. Der Artemis getaufte Chip stellt die zweite Generation der Eigenentwicklung dar, die erste Generation MTIA (Meta Training and Inference Accelerator) konnte 2022 die Erwartungen nicht erfüllen. Wie genau Artemis aufgebaut ist, ist nicht bekannt. Zu MTIA wissen wir hingegen, dass Meta einen ASIC mit einer... [mehr]
Eigentlich bereits für 2022 geplant, hat Meta nun damit begonnen, eine eigene Inferencing-Hardware in den Rechenzentren zu verbauen. Der Artemis getaufte Chip stellt die zweite Generation der Eigenentwicklung dar, die erste Generation MTIA (Meta Training and Inference Accelerator) konnte 2022 die Erwartungen nicht erfüllen. Wie genau Artemis aufgebaut ist, ist nicht bekannt. Zu MTIA wissen wir hingegen, dass Meta einen ASIC mit einer... [mehr]
