
Werbung
Nun endlich war es soweit und NVIDIA hat erste Details zur Pascal-Architektur enthüllt. Auch ein erstes Produkt gibt es schon: Den GPU-Beschleuniger Tesla P100. In direkter Folge der Keynote hat NVIDIA nun weitere Details zur Pascal-Architektur veröffentlicht, die wir einmal zusammenfassen wollen. Der Fokus liegt dabei konkret auf der GP100-GPU mit Pascal-Architektur. Wer sich zunächst nur einen groben Überblick verschaffen möchte, der findet im Artikel zur Keynote alle wichtigen Informationen.
Noch ein paar Worte zur Fertigung. NVIDIA lässt bei TSMC in 16 nm fertigen. Der Chip hat eine Größe von 610 mm2. NVIDIA gibt eine Anzahl von 15,3 Milliarden Transistoren für die GPU an, während das gesamte Package 150 Milliarden Transistoren beinhalten soll. NVIDIA zählt hier allerdings auch Komponenten wie den Speicher und die Interconnects mit. Den HBM2 bringt NVIDIA auf dem Interposer unter und bindet darüber auch die vier Speicherchips an. Die Interposertechnologie stammt aus dem Hause TSMC und damit ist NVIDIA nicht auf einen weiteren Dienstleister für die Interposertechnologie angewiesen.

[h3]Die Pascal-Architektur[/h3]
Weiterhin ein zentraler Bestandteil der Architektur sind die Streaming Multiprocessors (SM). Der Aufbau sieht Graphics Processing Clusters (GPCs), Streaming Multiprocessors (SMs) und Speichercontroller vor, die in einem bestimmten System organisiert sind. GP100 besteht aus sechs GPCs, diese jeweils 10 SMs und diese wiederum besitzen jeweils 64 Shadereinheiten. Damit kommt damit auf insgesamt 3.840 Shadereinheiten (6x10x64). Dies gilt allerdings nur für den Vollausbau von GP100, denn auf der Tesla P100 kommen nur 56 SMs zum Einsatz, was wiederum in 3.584 Shadereinheiten resultiert. Acht Speichercontroller sind um die GPCs organisiert und haben ein 512 Bit breites Speicherinterface. Insgesamt bindet die GP100-GPU den HBM2 also mit 4.096 Bit an. Neben den 64 Shadereinheiten befinden sich in jedem SM auch noch vier Textureinheiten, so dass wir hier insgesamt auf 244 Textureinheiten kommen.
| Die technischen Daten der GP100-GPU im Überblick | |||
|---|---|---|---|
| GPU | GP100 | Fiji XT | GM200 |
| Fertigung | 16 nm | 28 nm | 28 nm |
| Transistoren | 15,3 Milliarden | 8,9 Milliarden | 8 Milliarden |
| Speichertakt | 737 MHz | 500 MHz | 1.750 MHz |
| Speichertyp | HBM2 | HBM | GDDR5 |
| Speichergröße | 16 GB | 4 GB | 6 GB |
| Speicherinterface | 4.096 Bit | 4.096 Bit | 384 Bit |
| DirectX-Version | 12 | 12 | 12 |
| Shadereinheiten | 3.840 | 4.096 | 2.816 |
| Textureinheiten | 224 | 256 | 176 |
| ROPs | - | 64 | 96 |
| Typische Boardpower | 300 W | 275 W | 250 W |
| SLI/CrossFire | - | CrossFire | SLI |
Nicht unerwähnt ließ NVIDIA eine weitere Steigerung bei der Effizienz. Diese ist auf der einen Seite auf die Fertigung in 16 nm FinFET zurückzuführen. Änderungen in der Architektur der SMs sollen aber zu weiteren Verbesserungen beigetragen haben. Insgesamt nennt NVIDIA für die Tesla P100 aber dennoch eine maximale Leistungsaufnahme von 300 W.
Erstaunlich sind sicherlich die Taktraten der GP100-GPU auf der Tesla P100. Diese gibt NVIDIA mit einem Basis-Takt von 1.328 und einem Boost-Takt vn 1.480 MHz an. Natürlich sind durch die kleinere Fertigung höhere Taktraten möglich. Für eine GPU auf einer Tesla-Beschleunigerkarte sind die 1.480 MHz aber doch recht erstaunlich.
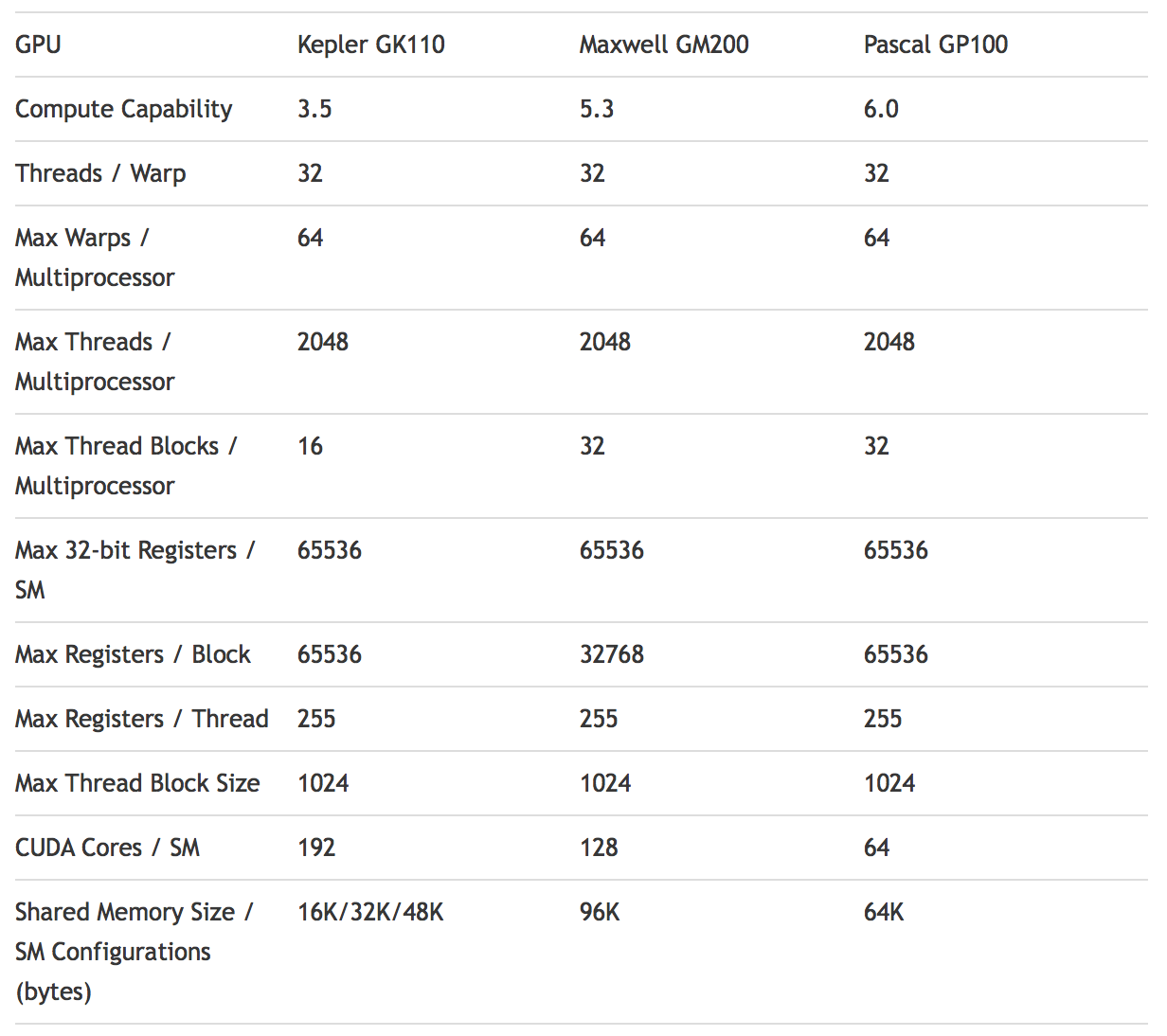
In der Folge schauen wir uns den Aufbau einer Streaming Multiprocessors noch einmal etwas genauer an. Bereits angesprochen haben wir die 64 Shadereinheiten pro SM. Dabei handelt es sich um FP32-Recheneinheiten. Maxwell und Kepler hatten 128 bzw. 192 FP32-Rechenheiten pro SM und legten den Fokus daher klar auf die Single-Precision-Performance. Jeder SM in der GP100-GPU ist in zwei Processing Blocks aufgeteilt. Jeder davon hat 32 Shadereinheiten, einen Instruction Buffer, einen Warp Scheduler und zwei Dispatch Units. Während die SMs in Pascal also die Hälfte an Shadereinheiten im Vergleich zu Maxwell tragen, sind die Größe der Register, Warps und Thread Blocks identisch geblieben.


Blockdiagramm der GP100-GPU und der SMs
Da sich die Anzahl der SMs aber dramatisch erhöht hat, ist auch die Größe der Register insgesamt stark angestiegen. NVIDIA hat auch den Datenpfad bzw. dessen Organisation optimiert. Letztendlich konnte NVIDIA die Die-Fläche reduzieren und auch die Leistungsaufnahme in diesem Bereich ist deutlich geringer. Dies ist einer der Bereiche, der zur Effizienzsteigerung geführt hat. Die neue Scheduler-Architektur sorgt für eine bessere Auslastung der Pipelines und jeder Warp Schedular kann zwei Warp Instructions pro Takt zuteilen.
[h3]Höhere Double-Precision-Performance[/h3]
Ein Fokus bei der Entwicklung der Pascal-Architektur, die drei Jahre und zwischen 2 und 3 Milliarden US-Dollar gekostet hat, lag bei der Double-Precision-Performance sowie der Leistung bei Anwendungen, die für Deep-Learning-Netzwerke wichtig sind.
| Rechenleistung von GPU-Beschleunigern im Überblick | |||||
|---|---|---|---|---|---|
| Modell | NVIDIA Tesla P100 | NVIDIA Tesla K80 | NVIDIA Tesla M40 | AMD FirePro S9300 X2 | AMD FirePro S9150 |
| GPU | GP100 | 2x GK210 | GM200 | 2x Fiji | Hawaii |
| FP64 | 5,3 TFLOPS | 2,91 TFLOPS | 214 GFLOPS | 800 GFLOPS | 2,53 TFLOPS |
| FP32 | 10,6 TFLOPS | 8,74 TFLOPS | 6,844 TFLOPS | 13,9 TFLOPS | 5,07 TFLOPS |
| FP16 | 21,2 TFLOPS | - | - | - | - |
| FP64/FP32-Verhältnis | 1/2 | 1/3 | 1/32 | 1/16 | 1/2 |
| Speichertyp | HBM2 | GDDR5 | GDDR5 | HBM | GDDR5 |
| Speichergröße | 16 GB | 2x 12 GB | 12 GB | 2x 4 GB | 16 GB |
| Speicherinterface | 4.096 Bit | 384 Bit | 384 Bit | 2x 4.096 Bit | 512 Bit |
| Speicherbandbreite | 720 GB/s | 2x 240 GB/s | 288 GB/s | 2x 512 GB/s | 320 GB/s |
| Shadereinheiten | 3.840 | 4.992 | 3.072 | 8.192 | 2.816 |
Für die deutlich bessere Double-Precision-Performance hat NVIDIA die Verhältnisse für die Funktion von FP64 und FP32-Recheneinheiten geändert. Während dieses bei der Kepler-Architektur noch bei 1/3 lag und in der vorherigen Maxwell-Architektur 1/32 betrug, sieht NVIDIA für die Pascal-Architektur ein Verhältnis von 1/2 vor.
Für Deep-Learning-Netzwerke sind Half-Precision-Berechnungen bzw. FP16-Berechnungen besonders wichtig und daher sieht hier NVIDIA auch ein Verhältnis von 1/2 zu den FP32-Berechnungen vor. NVIDIA hat das Handling dieser FP16-Berechnungen geändert, um von den dedizierten FP32-Kernen profitieren zu können. Dazu werden FP16-Berechnungen zusammengelegt, damit sie auf FP32-Kernen ausgeführt werden können. Damit die FP16-Berechnungen zusammengelegt werden können, müssen sie allerdings die gleichen Operationen ausführen. Zum Beispiel können nur zwei Additionen oder zwei Multiplikationen zusammengeführt werden. FP16-Operationen sind für Spielen bzw. dort der Verarbeitung von Texturen wichtig oder aber bei der Analyse von Foto- und Videodaten.
[h3]HBM2[/h3]
Die Pascal-Architektur sieht auch einige Optimierungen vor, die der Verwendung von HBM2 zu Gute kommen. Damit ist aber nicht nur die Breite des Speicherinterfaces gemeint, die mit 4.096 Bit ordentlich angewachsen ist, sondern auch das Handling von Atomic Speicheroperationen. Dabei handelt es sich um Schreib- und Lesezugriffe auf den Speicher. Bereits Kepler sah hier ein großes Optimierungspotenzial vor und mit Fermi machte NVIDIA einen weiteren Schritt zur Implementierung dieser Atomic Speicheroperationen. Mit Maxwell führte NVIDIA die native Hardware-Unterstützung für Shared Memory Atomic Operations in 32 Bit Integer sowie 32- und 64-Bit Compare-and-Swap (CAS) ein. Mit GP100 fügt NVIDIA nun noch FP64 Atomic Adds hinzu. Bei vorherigen Architekturen musste dies noch durch Compare-and-Swap Loop durchgeführt werden, was natürlich nicht so schnell sein konnte, wie eine native Lösung.


Tesla-P100-Modul in der Vorder- und Rückansicht
Der HBM2 selbst stammt aus dem Hause Samsung. NVIDIA verwendet vier HBM2-Chips mit einer Speicherkapazität von jeweils 4 GB. Diese Speicherchips bestehen aus vier Lagen und diese werden mit über 5.000 TSVs (Through Silicon Vias) und Microbumbs miteinander verbunden. Ein Interposer stellt die Verbindung zwischen Speicherchips und GPUs her. Auf die Interposer-Technologie sind wir in einem gesonderten Artikel bereits genauer eingegangen. Das komplette Packet aus GPU, HBM2 und Interposer befindet sich in einem 55 x 55 mm großen BGA-Package.
Über ein 4.096 Bit breites (4x 1.024 Bit) Speicherinterface bindet NVIDIA die Speicherchips an. Die Gesamtkapazität beträgt wie gesagt 16 GB und die Fehlerkorrektur ECC ist im Speicherstandard bereits integriert. Damit ist auch keine Reduzierung der Speicherkapazität durch ECC vorhanden und auch die Leistung wird nicht eingeschränkt. NVIDIA spricht von einer Speicherbandbreite von 720 GB/s und damit takten die HBM2-Chips mit etwa 740 MHz.
[h3]NVLink[/h3]
Neben der GPU selbst und dem HBM2 ist NVLink das dritte wichtige Feature für GP100 bzw. die Pascal-Architektur. Im Consumer-Bereich wird NVLink allerdings keine Rolle spielen. Dennoch ist es ein Bestandteil und daher werden wir auch auf NVLink noch einmal eingehen. NVLink soll die Kommunikation zwischen GPUs deutlich beschleunigen. 16 PCI-Express-3.0-Lanes erreichen eine Bandbreite von 15,75 GB pro Sekunde bzw. 128 GT/s. Intel bietet bei seinen Knights Landing Xeon Phi Beschleunigern solche mit Omni Path Interconnect an, was den Bedarf nach schnellen Interconnects unterstreicht. NVLink ermöglicht zudem eine Implementierung von Unified Memory auf allen miteinander verbundenen GPUs und dem dazugehörigen Speicher. Eine Tesla P100 kann damit auf Daten zugreifen, die im Speicher einer anderen Tesla P100 liegen.
NVLink wiederum basiert auf einem neuen High-Speed Signaling interconnect (NVHS). Eine NVHS-Verbindung mit einer Bandbreite von 20 GBit/s wird über ein Differential Connection ermöglicht. Acht dieser Connections ergeben einen Sub-Link. Zwei Sub-Links stellen wiederum einen Link dar und eben ein solcher Link stellt die Verbindungen zwischen zwei GPUs (GPU-to-GPU oder GPU-to-CPU) sicher. Ein solcher Link hat eine Bandbreite von 40 GB/s in beide Richtungen und für den eigentlichen Datentransfer stehen 97 Prozent dieser Bandbreite zur Verfügung. Damit ist der Overhead sehr gering.
Eine GP100-GPU verfügt über vier Links. Diese Links können auch zu Gangs zusammengefasst werden. Im Falle einer GP100-GPU bedeutet dies eine maximale Bandbreite für eine Verbindung von 160 GB/s. Theoretisch sind aber auch vier einzelne Links oder zwei Gangs zu jeweils 80 GB/s denkbar. Welche Art von NVLink-Struktur in einem Server genutzt wird, hängt davon ab, welchem Einsatzzweck diesen dienen sollen.
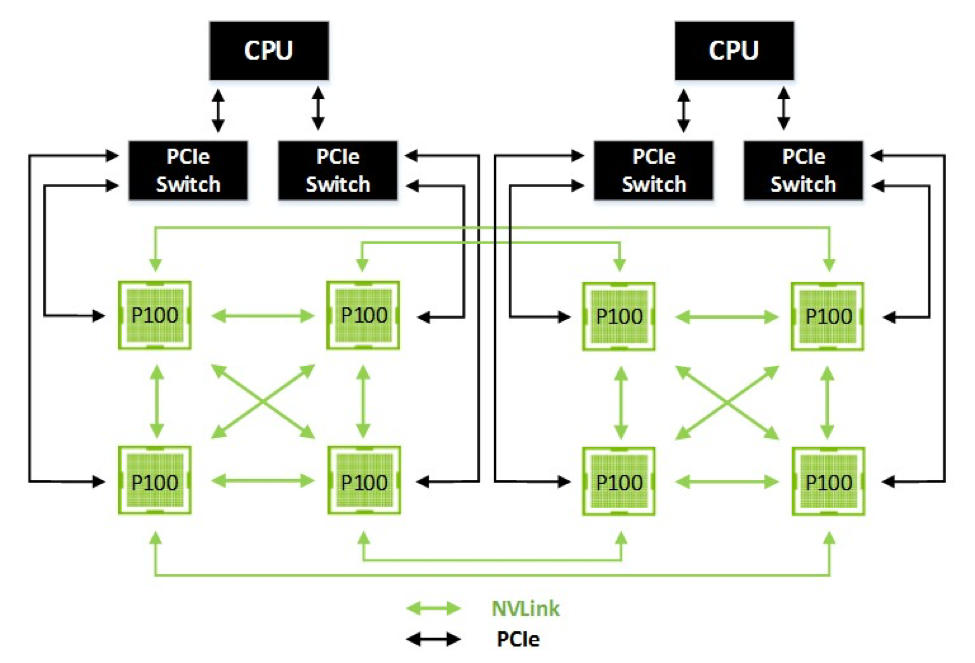
Ein Beispiel ist die Verbindung von acht GP100-GPUs, wie sie auf der Tesla P100 verbaut sind. In Quads zu jeweils vier Tesla P100 aufgeteilt stellen diese jeweils eine Verbindung untereinander her, während die beiden Blöcke ebenfalls via NVLink miteinander verbunden sind. Die Verbindung zu den zwei CPUs wird in diesem Fall über PCI-Express realisiert.
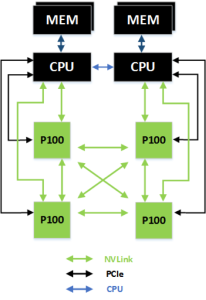
IBM ist einer der ersten Hersteller, der NVLink in seine CPUs eingebaut hat. Entsprechende Server mit Tesla P100 Beschleunigern verbinden sich untereinander weiterhin mittels NVLink – in diesem Fall gilt dies aber auch für CPUs.
[h3]Unified Memory[/h3]
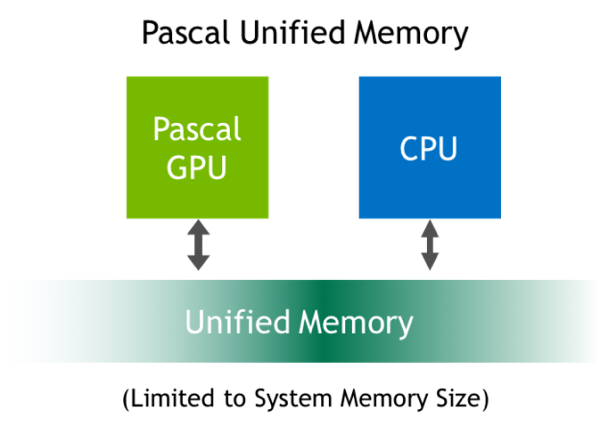
Unified Memory ist kein neues Feature bei den GPUs, allerdings hat NVIDIA die Pascal-Architektur angepasst, damit der Speicher über weitere Bereiche eines solches Systems erreichbar ist. Unified Memory wurde mit CUDA 6 eingeführt, besitzt bei der Kepler- und Maxwell-Architektur aber noch einige Einschränkungen. So kann die CPU nicht auf den Speicher der GPU zugreifen, ohne das dieser zuvor synchronisiert wird. Ein gleichzeitiger Zugriff auf einen bestimmten Bereich des Speichers war ebenso nicht möglich. Außerdem war die Größe des Unified Memory auf die des Grafikspeichers limitiert.
Mit Pascal bzw. CUDA 8 führt NVIDIA einen virtuellen Speicher ein, der einen Adressraum von 49 Bit vorzuweisen hat. Damit ist dieser groß genug, um sämtlichen Speicher von CPUs und GPUs in einem System zu umfassen. Der Unified Memory ist also nicht mehr auf die Größe des Grafikspeichers limitiert. NVIDIA spricht von einer maximalen Größe von 192 TB für den Unified Memory.
Neben der reinen Speichergröße bietet der Unified Memory in der aktuellen Version auch noch einige Funktionen, die das Handling mit dem Speicher vereinfachen. Page Faulting ist eine der neuen Funktionen. GPUs und CPUs können bestimmte Speicherbereiche eigenständig verwalten, ohne das eine stände Synchronisation notwendig ist. Davon nicht betroffen ist die Kohärenz des Speichers, die in jedem Fall gegeben ist. Entwickler müssten allerdings aufpassen, dass sie im Falle von Page Faulting keine Daten wegwerfen, die andere CPUs und GPUs womöglich noch benötigen. Dann muss dennoch zunächst eine Synchronisation erfolgen, um einen Datenverlust zu verhindern.
Bestimmte Betriebssystem nutzen den Unified Memory auch derart, dass dieser Speicher der Default-Speicher ist. Damit können auch Standardanweisungen wie Malloc oder New verwendet werden. Auch bei den Pointern sind keine Anpassungen notwendig, da der Unified Memory für das Betriebssystem komplett zugänglich ist. Speicherarrays können dabei auch größer werden, als es der eigenen Speicher der CPU und GPU zulassen würden – es wird einfach der Speicher der anderen CPUs und GPUs verwendet. Damit können auch extrem große Datenmengen verarbeitet werden.
Soweit zunächst einmal die Details zur Pascal-Architektur und der Tesla P100 als erste Karte mit dieser GPU. NVIDIA produziert nach eigenen Angaben bereits Tesla P100 Karten und liefert diese auch schon in Kürze aus. Spannend ist nun die Frage, ob und wann mit GeForce-Karten mit GP100-GPU zu rechnen ist. HBM2 dürfte hier noch immer der limitierende Faktor sein. Wahrscheinlich wird zunächst eine kleinere GPU auf Basis der Pascal-Architektur erscheinen, die dann auch zunächst auf GDDR5 oder GDDR5X setzen wird. Details dazu sind auf der GPU Technology Conference aber nicht zu erfahren, da NVIDIA aktuell noch nicht über solche Produkte spricht.
