
Werbung
Im Rahmen der Einführung in das Thema DirectCompute versuchte NVIDIA die Frage zu beantworten, warum überhaupt GPUs verwendet werden sollen, um komplizierte Berechnungen durchzuführen. GPUs bieten in der Theorie eine höhere Rechenleistung, als dies aktuell CPUs können. Reduziert auf die Anzahl der FLOPs liegen GPUs sowohl bei der Rechenleistung unter DirectX 10 und 11 auf Hardware-Basis deutlich vor den modernen Prozessoren. Doch so ohne weiteres ist dies nicht möglich, denn eine effiziente Verarbeitung von Daten kann nur über eine Aufteilung eines Problems oder einer Aufgabe in viele kleine erfolgen. Soweit keine Überraschungen, denn dies ist bereits seit geraumer Zeit bekannt und wird auch dadurch deutlich, dass Prozessoren über immer mehr Kerne verfügen und sowohl dort, als auch bei den GPUs, die Verarbeitung auf möglichst vielen Kernen Vorrang vor dem Takt hat.
{jphoto image=2705}


Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
GPUs bieten einen hohen Daten-Durchfluss, aber auch eine hohe Speicher-Latancy. Daher muss die Zuteilung der Speicheradressen zum jeweiligen Thread intelligent erfolgen. Konflikte beim Zugriff sind dabei natürlich zu vermeiden.

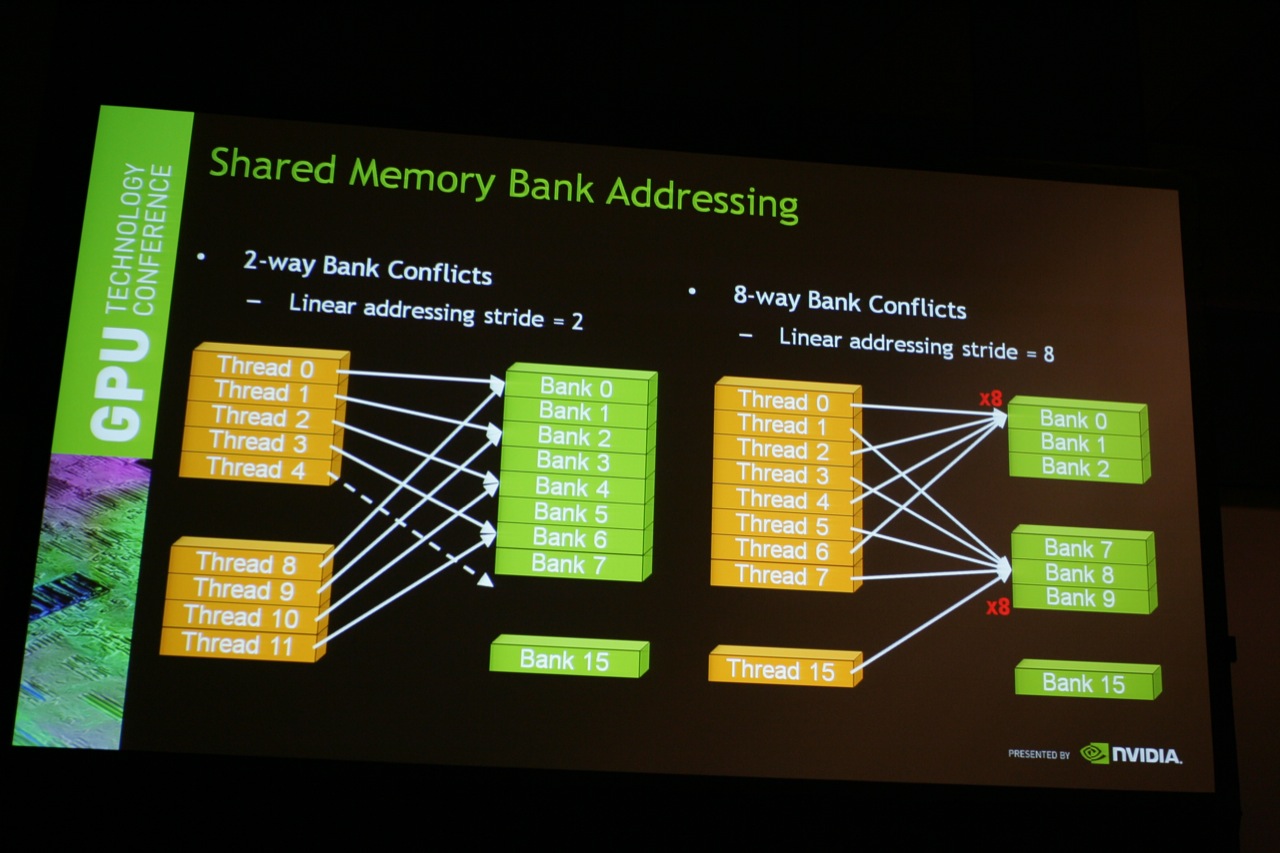
Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
Eine effektive Nutzung der GPUs setzt verschiedene Gegegebenheiten voraus. So gilt bereits bei der Programmierung zu beachten, dass pro Hardware-Shader-Unit 8 Thread-Groups maximal zur Verfügung stehen. Noch weitaus wichtiger ist die limitierte shared-Memory von 48 kB. In jeder Hardware-Shader-Unit können bis zu 1536 Threads gleichzeitig ausgeführt werden.

Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
Eine hohe Effektivität wird auch nur dann erreicht, wenn alle Multiprozessoren auch genutzt werden. Die anfallenden Threads werden also in Thread-Groups zusammengeführt und jeder Multiprozessor sollte mindestens eine Thread-Group zur Verarbeitung vorliegen haben. Ein großes Problem ist aber der Austausch von Daten zwischen den verschiedenen Multiprozessoren innerhalb der Thread-Groups. Eine Möglichkeit wäre es die Daten global auf allen Multiprozessoren zu synchronisieren, was allerdings zu einem gewissen Overload führt, da auch Daten übertragen werden, die nur von einer weiteren Instanz verwendet werden. Es empfiehlt sich also die Daten gezielt an die gewünschte Thread-Group zu übertragen, was dem Programmierer allerdings einen höheren Code-Aufwand abverlangt. Möglich macht dies ein sogenannter Thread Group Shared Memory, der angelegt wird und zwischen verschiedenen Thread-Groups einen Datenaustausch erlaubt.
Werden Daten aber einer GPU zwischen der ALU und dem Speicher ausgetauscht, gehört zu jedem Datenblock ein gewisser Anteil an Informationen, welche die Adresse innerhalb des Speichers und weitere Details enthalten. Mit höherer Datenrate wird dieser Overhead ebenfalls immer größer und behindern eine vernünftige Skalierung der Performance. NVIDIA hat einige Mittel und Wege gefunden diesen Overhead zu reduzieren, was sich letztendlich in einer höheren effektiven Bandbreite niederschlägt.
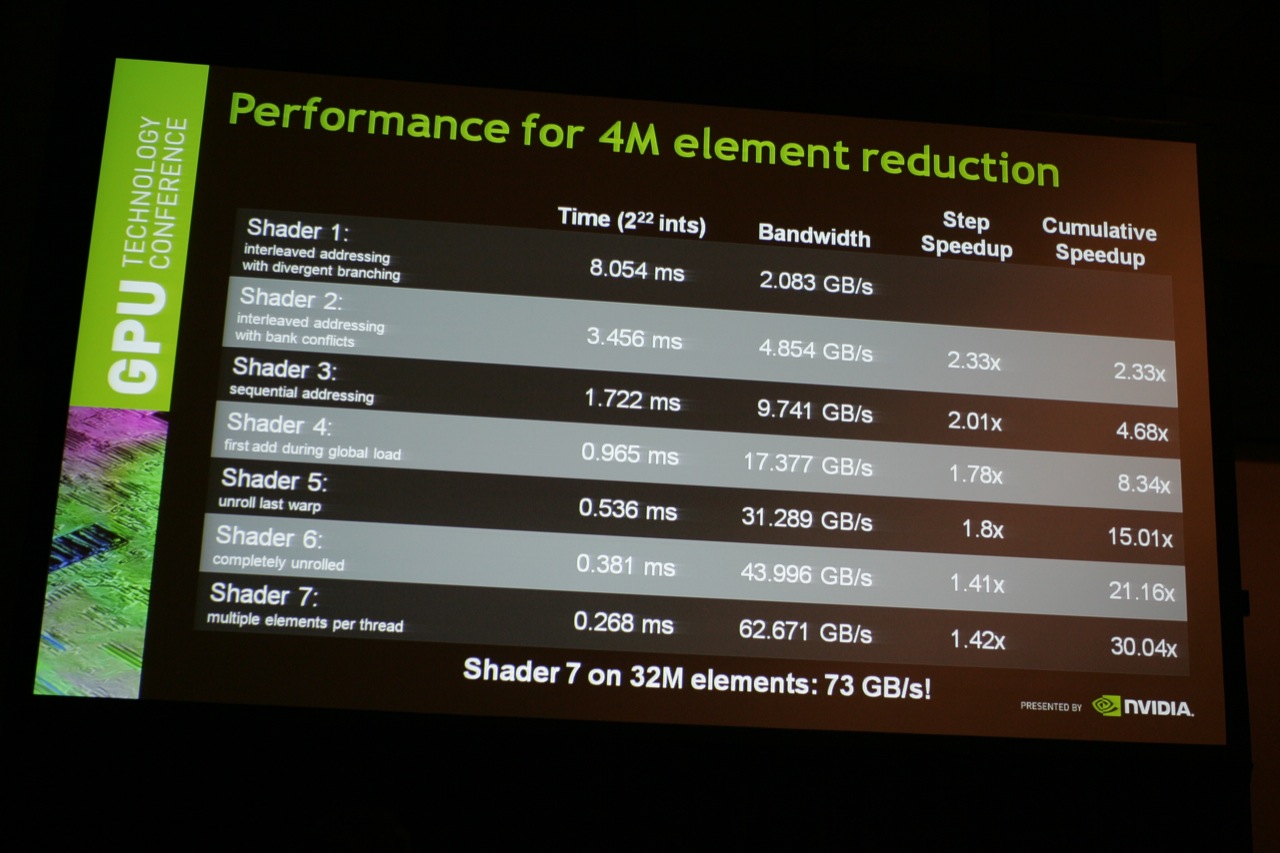
Durch Klick auf das Bild gelangt man zu einer vergrößerten Ansicht
DirectCompute kann bei effektiver Programmierung also hochoptimierte Aufgaben übernehmen. Ein Beispiel ist an dieser Stelle die Rauschreduzierung auf Fotos. Ein Video stellt die Abarbeitung der verschiedenen Rausch-Frequenzen dar. Links ist Originalfoto zu sehen, rechts das überarbeitete. Eine weitere Anwendung das Einfügen eines Lens-Flare-Effekts in einer 3D-Szene oder die Verarbeitung von HDR-Fotos. Beides haben wir in einem Video zusammengeführt.
Ein großes Einsatzgebiet von DirectCompute zur Berechnung von rechenintensiven Daten, ist die Darstellung von Flüssigkeiten und hier Speziellen die Simulation von Wellen.
Weitere Links:
